
Updated 2024-09-17 to reflect updated PgBouncer support for protocol-level prepared statements 🐘
To start, I want to say that I’m appreciative that PgBouncer exists and the work its open source maintainers put into it. I also love working with PostgreSQL, and I’m thankful for the incredible amount of work and improvements that go into it as well.
I also think community and industry enthusiasm around Postgres is at an all time high. There are more managed hosting options than ever (Crunchy Data, Render, Fly.io, and on and on), deep extensions like PostgresML, Citus and Timescale, serverless options like Neon, and real-time services like Supabase with Postgres at their center. Postgres is a robust, advanced and fast RDBMS capable of handling the needs of most every application.
I just find the current state of recommendations and guidance around scaling Postgres to be confounding. And it feels surprising for new Postgres users to discover that one of the most common scaling options relies on a solution like PgBouncer.
Over the years I’ve read dozens of articles around scaling and maintaining Postgres databases, and they always understate the impact of PgBouncer on your application. They casually mention unusable features without any exploration, or the numerous ways you can silently break expected query behavior. The advice is just to turn it on. I want it to be clear that as your application scales, PgBouncer is often necessary but isn’t free.
The following sections provide an overview of what connection pooling is in general, how connection pooling modes work in PgBouncer and similar tools, and then I dig into every Postgres feature that does not work in PgBouncer transaction mode and what the implications are. This is the PgBouncer article I wish existed the first time I used it - let’s get going 🐘!
Contents
- What is connection pooling?
- Why do I need a separate tool from Postgres?
- Can I just turn on PgBouncer and get scaling for free?
- Perils
- Detecting invalid statements 😑
- Lock timeouts (SET/RESET) 🔓
- Statement timeouts (SET/RESET) ⏳
- Transparency 👻
- Prepared Statements (PREPARE/DEALLOCATE, Protocol-level prepared plans) ✔️
- Pool throughout / Long running queries 🏃♂️
- Session Level Advisory Locks 🔐
- Listen/Notify 📣
- The single thread 🪡
- pg_dump 🚮
- Other unavailable features 🫥
- Linting 🧶
- Can we improve connections without a pooler?
- PgBouncer alternatives
What is connection pooling?
PgBouncer is a lightweight connection pooler for PostgreSQL. What does that mean exactly? What is connection pooling and why is it needed?
Opening a connection is expensive: a new Postgres client connection involves TCP setup, process creation and backend initialization – all of which are costly in terms of time and system resources. A connection pool keeps a set of connections available for reuse so we can avoid that overhead past initial connection.
There are three main levels of connection pooling1:
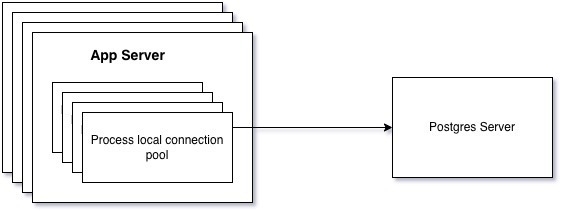
Framework connection pooling. This is a common feature of many frameworks/libraries. Within a given process, you maintain a pool of active connections that are shared between code, generally running across threads. Whenever you handle some processing in a server request, a background process, a job, etc, you open a connection and keep that connection open. When that piece of work finishes and a new piece of work starts, you can reuse the connection without the expense of opening a new connection to the database every single time. These connections are usually local to a particular operating system process, so you gain no benefit outside of that process (and if you’re scaling Postgres, you probably have lots of processes)
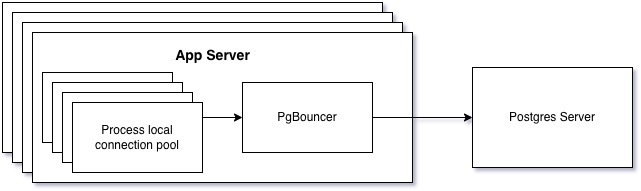
One level higher, you can have client level connection pooling outside of your code. PgBouncer can handle this, and instead of independent unsharable process-isolated connections you proxy all of your connections through PgBouncer. But it runs on your server, so you still cannot share connections between servers (and again, when needing to do it you probably have lots of servers).
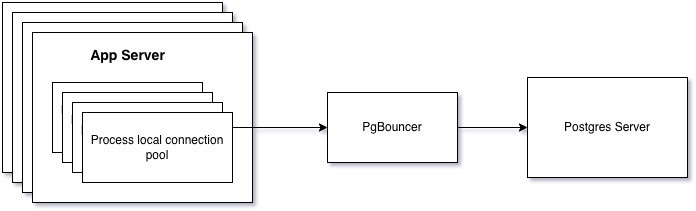
Server level connection pooling. Here we host PgBouncer independent of our servers and connect to a single central PgBouncer instance2. This is the most robust form of connection pooling because independent of anything else in your code or server, you are guaranteed that any client connection is coming from the pool.
Why do I need a separate tool from Postgres?
That’s all great but… why do we need it?
There are two primary layers to this:
- Maintaining connections is beneficial as a base feature. Less memory and io churn, less latency before running queries. Less pressure on the database constantly opening and closing connections.
- Postgres connections get expensive very quickly. Surprisingly quickly.
Here are some general community guidelines around allowable Postgres connection counts based on a mixture of community experience and specific benchmarking:
- In terms of what some managed services even offer: Supabase offers a max of 50 connections, Neon offers a max of 100 connections, and Render offers a max of 397 connections.
- The general upper bound recommendation is a max of 500 active connections. Services like Heroku Postgres even enforce a hard limit of 500 connections3
- Even at 500 connections, your server is going to be strained. This more recent (as of 2023) enterprisedb article analyzed connection performance and found that 300-400 active connections seems optimal. This article from Brandur is older (2018) but seems to reinforce this idea as well
- There have been some more recent connection improvements in Postgres (as of version 14) handling idle connections more efficiently4, but active connections are still expensive5 and idle connections have not reached the scale of a dedicated pooler
- The reality of 500 connections is it sounds extremely low but those connections can handle a ton of throughput. The problem is, as a metric of pure concurrency, real connections have a hard upper limit. So if you try to have five thousand clients connect simultaneously, you’re going to start getting loads of connection errors6.
To improve the cost of connection overhead, general connection pooling is helpful and a PgBouncer instance in its default session based mode can handle it. But to improve concurrency things have to get a bit… quirky.
There are two modes in PgBouncer which give clients access to more connections than Postgres actually has available. They rely on the idea that at any given time many of your connections are idle, so you can free up usage of idle connections to improve concurrency.
Can I just turn on PgBouncer and get scaling for free?
Kind of? But not really? It’s complicated.
Internally, PgBouncer will manage a pool of connections for you. The default pooling mode it starts with, session pooling, is conservative, and in most cases will not provide improved concurrency7.
I’m going to hand wave a bit past two of the modes and focus on the typical recommendation.
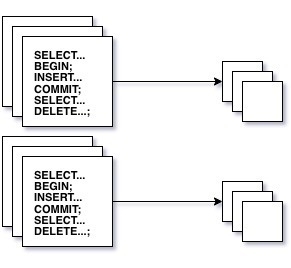
Session mode is the default and most conservative mode. This is a 1:1 - your local connection truly holds onto a full connection until you close it. This does little to help you scale connection concurrency, but it helps with latency and connection churn overhead.
Statement mode is the most aggressive mode and means your connection goes back into the pool after every statement. You lose the ability to use transactions 😰 - that seems wild and unusable for only the most specialized of use cases.
The mode that results in a more sane balance of improved concurrency and retained critical database features is transaction mode. Transaction mode means your connection stays consistent as long as you’re in a transaction. Once the transaction finishes, your code thinks it still has real connection but PgBouncer actually releases the connection back into the pool internally. This is session sharing, your session is going to be shared with other connections without being reset or closed.
Transaction mode is a powerful concept. Your code in general has lots of database downtime. Most code does not solely operate on the database - it takes CPU cycles, interacts with files, makes network calls, and calls other data stores. During that time, your connection sits idle and unused for what in computing and database terms is an eternity. By releasing that back into the pool outside of transactions you free up your idle connection for use by a client who actually needs it. This way your 500 available connections can services thousands of clients, instead of a 1:1 with the number of available connections.
-- connection is actually pulled from the pool inside PgBouncer
BEGIN;
INSERT INTO...;
UPDATE;
COMMIT;
-- connection goes back to the pool inside PgBouncer
The problem with transaction mode is that this tiny configuration change quietly changes not only your ability to scale, but also the way your connections behave. It breaks the expected command semantics between client and database server. And understanding whether you’ve gotten things right in transaction mode is very difficult.
Let’s say you’ve been operating with PgBouncer in session mode (or operating without a proxy at all), and you make the switch to transaction mode. Your perspective on how you can use Postgres needs to change - so now we’re onto the peril.
Perils
Many of the following items are documented shortcomings of PgBouncer in transaction mode. But:
- They’re treated lightly
- Their repercussions and downsides are not discussed
- PgBouncer is often recommended without mentioning them
- PgBouncer is often recommended at the same time as recommending incompatible transaction mode features like session level advisory locks and session level statement timeouts
- The non-determinism introduced by using incompatible statements is not discussed (ie, I execute a statement in Process A and suddenly Process B errors out due to it)
Assume anytime I mention PgBouncer after this point I am referring to transaction mode. Here we go!
Detecting invalid statements 😑
PgBouncer happily accepts statements that are not supported in transaction mode. The problem is pushed onto the developer, which means they can and will get it wrong8.
This is by design. The sense I get is that PgBouncer was specifically architected to not analyze any statements and so it would be a big change for them to handle this9.
Amazon has a similar tool to PgBouncer called RDS Proxy, and it has a feature called “connection pinning”. If it detects a statement that is incompatible with transaction mode, it will automatically hold that connection for that client for the duration of their session.
This is both highly useful and simultaneously problematic. It means query behavior is consistent with your expectations (🙌🏼) but also that you can silently kill all concurrency benefits (😑). If enough queries are run that trigger connection pinning, all of a sudden you may throttle your throughput. But it does give you an escape hatch for safely running statements which are not transaction compatible without having to jump through any hoops.
I’d be fine with some logging I could monitor. As far as I can tell there is nothing like this in PgBouncer, and so all the burden lands on you to get it right. As one engineer, or a few engineers, all aware of potential issues, you can probably maintain that. But what about dozens of engineers? Or hundreds? Thousands? All with varying levels of experience with databases and poolers? There’s going to be mistakes.
Lock Timeouts (SET/RESET) 🔓
Unless you like app downtime, you should be using a lock_timeout when running DDL. It’s a critical aspect of zero downtime migrations.
The idea is to set it to a limit that would be acceptable for queries in your application to slowdown by - waiting to acquire a lock can cause related queries to queue up behind your DDL operation:
-- slow select
SELECT * FROM my_table;
-- DDL starts in separate process, blocked on acquiring the lock by the
-- slow query
ALTER TABLE my_table...
-- Subsequent queries start queuing up...
SELECT * FROM my_table WHERE id = 123;
SELECT * FROM my_table WHERE id = 234;
--- ...
In that scenario, the slow query is running the show. Until it finishes, all the other queries to that table are stuck. That goes on long enough and users can’t use the system. A bit longer and your app starts timing out. A bit longer you’re running out of connections. Now you’re staring at a total app outage, about ready to kill all of your connections in a desperate attempt to salvage things, contemplating a career change to landscaping where you can at most impact one person at a time, right? That sounds nice, doesn’t it?
I’ve of course never experienced that. I’m just very creative 💀. But if you have experienced that, or you’d like to avoid experiencing that, use a lock_timeout:
SET lock_timeout TO '2s';
Now if your DDL cannot acquire a lock it will throw an error after 2 seconds. That should be an ok delay in running queries, and you can retry the operation later.
But wait! Are you connected to PgBouncer?! You may want to bring up that landscaping help-wanted listing again… 🌳
SET operations apply at the session level. This means that on a PgBouncer connection, there is no guarantee our lock_timeout will still be applied when we run our DDL:
-- Process 1
-- PgBouncer pulls connection 1
SET lock_timeout TO '2s';
-- connection 1 goes back to the pool
-- Meanwhile, in Process 2:
-- PgBouncer pulls connection 3
SELECT id FROM my_table, pg_sleep(30);
-- Back in Process 1:
-- PgBouncer pulls connection 2
-- This connection has no lock_timeout set, so it will hang
-- until our pg_sleep query finishes 30 seconds later, and all
-- queries to my_table after it are stuck for those 30 seconds as well
ALTER TABLE my_table...
It’d be easy to argue “don’t have slow queries”. And that should be the goal! But we don’t call it “happy path uptime 🌼”, we call it “zero downtime”. It means even if things go wrong, you don’t go down. There can also be other operations that hold a lock on your table, so you simply can’t rely on successfully acquiring that lock10.
So what can we do? There are two options:
- Bypass PgBouncer and go straight to the database
- Use a transaction level
lock_timeout
Bypassing PgBouncer
Your safest bet is to go with option (1). You should have some ability to directly connect to your database, so take advantage of it and don’t jump through hoops to run DDL safely.
The biggest obstacle you hit with (1) is transparency: PgBouncer really doesn’t want you to know whether you are connected to the real database or not. There’s no easy answer there, but by validating a setup where you consistently run your DDL process directly against Postgres then you’re set.
Use transaction level statements
There is a transaction local equivalent to the SET statement: SET LOCAL. Using our example from earlier:
-- Process 1
-- PgBouncer pulls connection 1
BEGIN;
SET LOCAL lock_timeout TO '2s';
-- connection 1 stays checked out
-- Meanwhile, in Process 2:
-- PgBouncer pulls connection 3
SELECT id FROM my_table, pg_sleep(30);
-- Back in Process 1:
-- Connection 1 is still checked out
ALTER TABLE my_table...
-- lock_timeout raises an error after 2 seconds waiting, and
-- we avoid our downtime!
DDL in Postgres is transactional, so it’s valid to start our transaction, set our lock_timeout using SET LOCAL, then start our DDL operation. Our transaction local setting will stick with us until the transaction commits or rolls back, so we safely keep our timeout and rollback our DDL.
It’s not a terrible solution (1 is still better), except for two things:
- Concurrent indexes
- Tooling
Another zero downtime star is the concurrent index. When you create a new index on a table you run the chance of locking it up long enough to cause downtime. Here’s the answer to that problem:
CREATE INDEX CONCURRENTLY index_name ON my_table;
Concurrent indexes are created without an exclusive lock, so your normal operations keep going while it builds the index in the background. The problem is they can’t be run in a transaction, so SET LOCAL is not an option.
Because they don’t require an exclusive lock, setting a lock_timeout is less important. But if there is contention and you just can’t get that index to acquire it’s shared lock, do you really want it to run forever?
As for (2), popular tooling usually does not handle SET LOCAL for you. In the Rails/ActiveRecord world there are several libraries that will automatically apply zero downtime policies for you, but they all assume you have an exclusive connection and operate at the SET session level.
In PgBouncer, the road to downtime is paved with session level statements.
Just go with (1), keep your sanity, throw away the diary entries about living out your days breathing in the smell of fresh cut grass, and connect directly to Postgres to run DDL with SET lock_timeout calls.
Statement timeouts (SET/RESET) ⏳
Determined not to repeat your experiences from lock_timeout, you read about this thing called statement_timeout. This little magic wand makes it so you control how long a statement is allowed to run 🪄.
So here it is:
SET statement_timeout TO '2s';
Those greedy queries now don’t stand a chance. You can tame your long running queries and avoid blocking your DDL! You ignore my advice to always use lock_timeout, say “bye losers” to long running queries, and fire off that DDL again… oh god. Why are things slowing down. Now they’re timing out. The connections are filling up. What is happening?

Oh riiiight. You forgot. You’re using PgBouncer. SET is off the table. Should have set that lock_timeout 🔐…
If I had a nickel for every time someone mentioned SET statement_timeout and PgBouncer in the same article…11 I know no one sharing this content is doing it maliciously, but be aware that these are misleading and incompatible features.
With lock_timeout, why does statement_timeout even matter?
- Statement timeouts are helpful for long running queries so they cancel earlier. If a client disconnects, Postgres will periodically check for the connection and try to cancel the query when it goes away. But a query with runaway cpu usage will just keep running even if the client dies or disconnects. That means you lose that connection until the query finishes, which can take minutes (or hours)
- The database default is 0, which means there is no limit. In some contexts this is not a problem, but particularly for web requests this is excessive
The first time I used statement_timeout was from a blog recommendation to limit statements for requests in web applications. In a web request, you usually have an upper limit on how long you allow them to run before they time out - this conserves resources, protects against runaway buggy code and helps with bad actors. It made sense that I’d set it to something conservative on all my web connections to deal with long running queries.
I deployed the code and for a little while things seemed to work well. Then I saw something odd. This started popping up:
canceling statement due to statement timeout
But in my… background jobs? My web requests were tuned to be fast, but the constraints around my background processes were a bit… looser. Can you guess what I had recently enabled? PgBouncer in transaction mode. My session level statement timeout was being swapped out from my web request, picked up by my job, and caused my job to timeout instead - web request safety was off the rails and longer running jobs were intermittently failing.
So is there any way we can use it? There’s a couple ways I know of, but nothing great when pooling.
Our old friend transaction
BEGIN;
SET LOCAL statement_timeout '5s';
SELECT ...
COMMIT;
Something about wrapping a SELECT in a transaction feels kind of strange, but it works. If you have targeted concerns, you can wrap particular queries in a transaction and use SET LOCAL to localize the statement_timeout.
This is absolutely not a viable solution for a whole request lifecycle. If I wanted to attempt my web request level timeouts again, no way am I wrapping every web request in one giant transaction. Postgres doesn’t have a concept of nested transactions so any code I have that may be operating transactionally is gonna be in for some confusing surprises12. And most importantly, wrapping my whole request in a transaction means I’ve completely negated the benefit of proxy pooling - now my request lifecycles are basically 1:1 with my connection sessions.
Apply statement timeouts per user
I’ve never tried it, but I’ve seen it recommended to set statement timeouts per user when using PgBouncer. That seems to have a couple problems I can think of:
- It’s not dynamically configurable.
- It dilutes the pool of available connections per context
(1) is definitely inconvenient. If you have different contexts where you’d like to apply different timeout constraints, this would be way too cumbersome to maintain.
But (2) feels like a deal breaker. If I want to constrain my web requests to a conservative timeout, but give my background processes more wiggle room, my pool size of real connections is now split instead of sharing a pool of total available database connections. I also have to manage making sure each context uses the appropriate user, or things will go badly.
It’s technically an option, but seems trickier to maintain and monitor.
Transparency 👻

I don’t understand why my session features aren’t working. I always make sure to use plenty of Postgr…PgBouncer?!
It is very difficult to tell when you are or aren’t using PgBouncer, which is unfortunately by design. It considers itself a transparent proxy. In session mode, that’s pretty much true. But in transaction and statement mode you are working with bizarro Postgres. It all works the same except when it doesn’t.
So if you want a regular connection because you need a feature not available in transaction mode, being sure you did it right is extremely difficult.
I have had a hell of a time verifying that some servers are or aren’t running with PgBouncer. Server A is using pub sub, I don’t want it. Server B needs the throughput, I want it. How can I make sure someone never makes a mistake and attaches the server to the wrong place? Basically, I can’t.
When it comes to production code I like to be paranoid. On a large enough codebase, and team, and user base, unusual things are bound to happen, sometimes regularly. I try to write code and configure environments so the right way is easy and the wrong way is hard. PgBouncer does not make that easy.
On this particular point I’d love to say I have some kind of advice to act on, but it mostly takes testing and validating your setup. If someone out there has better ideas or tips, I am all ears.
Prepared Statements (PREPARE/DEALLOCATE, Protocol-level prepared plans) ✔️
📝 Update as of PgBouncer version 1.21 - protocol-level prepared statements are now supported! See this crunchy data article for more specifics.
PREPAREstyle statements will still never be supported, and there are still some gotchas with protocol-level support you can learn about in that article.Everything mentioned here is still relevant for versions < 1.21. As well, it still gives a thorough explanation of why “turning off” prepared statements while still utilizing
libpq(as most libraries do) is a-ok ✌️
PgBouncer has a public relations problem when it comes to prepared statements. This is all the PgBouncer docs say about them:
| Feature | Session pooling | Transaction pooling |
|---|---|---|
| `PREPARE` / `DEALLOCATE` | Yes | Never |
| Protocol-level prepared plans | Yes | No* |
* It is possible to add support for that into PgBouncer
Kind of feels… alarming. No prepared statements in transaction mode?! Aren’t those… important? Even further when you go to use PgBouncer with Hibernate or ActiveRecord (and I’m sure others) you’ll see the recommendation to configure them to turn off prepared statements 😱. Does it surprise you a bit to hear that? Make you feel a little queasy maybe?
I had it drilled into me early in my career that prepared statements are a critical part of protecting against SQL injection. In the OWASP SQL Injection Prevention Cheatsheet the very first recommendation is:
- Use of Prepared Statements (with Parameterized Queries)
So PgBouncer tells me I need to turn them off?

The first time I used PgBouncer in an application I spent a lot of time figuring out how turning off prepared statements was safe to do. It turns out that prepared statements in Postgres mean a few things, but come down to two main options:
- Named prepared statements
- Unnamed prepared statements
Named prepared statements are reusable, and are tied to the connection session.
Unnamed prepared statements are single use, and have no association to the connection session.
There are two ways to create a named prepared statement and one way to create an unnamed prepared statement:
PREPARE- Protocol-level Parse/Bind/Execute with a name specified
- Protocol-level Parse/Bind/Execute with no name specified
PgBouncer says it doesn’t support prepared statements in either PREPARE or protocol-level format. What it actually doesn’t support are named prepared statements in any form. That’s because named prepared statements live in the session and in transaction mode you can switch sessions.
-- PgBouncer pulls connection 1
PREPARE bouncer_since (int, timestamp) AS
SELECT *
FROM bouncers b
INNER JOIN guests g ON g.bouncer_id = b.id
WHERE b.id = $1 AND b.created > $2;
-- connection 1 goes back to the pool
-- PgBouncer pulls connection 2
EXECUTE bouncer_since(1, now() - INTERVAL '2 days');
-- 💣 ERROR: prepared statement "bouncer_since" does not exist 💣
But unnamed prepared statements are totally fine. In fact, I’d be shocked if the current client library you’re using to connect to Postgres does not already switch to them if “prepared statements” (again, so damn misleading) are “turned off”.
But wait. What the heck is an unnamed statement? PREPARE requires a name… how can I make a prepared statement without a name?
Protocol-level prepared plans

The alternative to the PREPARE statement is to directly communicate with Postgres at the protocol level.
I had to dig a bit to get a handle on this - I started from a common Ruby ORM called ActiveRecord, dug into the Ruby “pg” gem it uses, then went one layer deeper into libpq, which is part of Postgres itself.
If we use active record as an example, when prepared statements are “disabled”, the postgres adapter internally calls exec_no_cache in activerecord/lib/active_record/connection_adapters/postgresql_adapter.rb:
def exec_no_cache(sql, name, binds...)
#...
conn.exec_params(sql, type_casted_binds)
That’s powered by the ruby “pg” gem, which when calling exec_params from ruby ultimately calls into the libpq function PQsendQueryParams:
// Ruby "pg" gem
// ext/pg_connection.c
static VALUE
pgconn_async_exec_params(int argc, VALUE *argv, VALUE self) {}
// internally calls...
static VALUE
pgconn_send_query_params(int argc, VALUE *argv, VALUE self) {}
// internally calls this from the libpq c postgres internals:
// src/interfaces/libpq/fe-exec.c
int PQsendQueryParams(PGconn *conn,
const char *command,
int nParams,
const Oid *paramTypes,
const char *const *paramValues,
const int *paramLengths,
const int *paramFormats,
int resultFormat) {}
What does PQsendQueryParams do? It calls an internal method named PQsendQueryGuts. Notice the empty string and use unnamed statement comment 🤔.
return PQsendQueryGuts(conn,
command,
"", /* use unnamed statement */
nParams,
paramTypes,
paramValues,
paramLengths,
paramFormats,
resultFormat);
What does that function do (aside from making me laugh every time I read the name PQsendQueryGuts 😆)? Internally PQsendQueryGuts communicates with Postgres at the protocol level:
/* construct the Parse message */
if (pqPutMsgStart('P', conn) < 0 ||
pqPuts(stmtName, conn) < 0 ||
pqPuts(command, conn) < 0) {}
/* Construct the Bind message */
if (pqPutMsgStart('B', conn) < 0 ||
pqPuts("", conn) < 0 ||
pqPuts(stmtName, conn) < 0) {}
/* construct the Execute message */
if (pqPutMsgStart('E', conn) < 0 ||
pqPuts("", conn) < 0 ||
pqPutInt(0, 4, conn) < 0 ||
pqPutMsgEnd(conn) < 0) {}
This is the Parse/Bind/Execute process I mentioned earlier.
- The code sends a Parse message with the query and an optional name. In our case the name is empty
- The code then Binds params to that query (if the query is parameterized)
- It then Executes using the combination of the parsed query and the bound params
This is perfectly safe to do in transaction mode, and from a SQL safety perspective should behave identically to a named prepared statement.
Named protocol-level statements
For comparison, when ActiveRecord has prepared statements turned on, things look a bit different, but by the end we’re in the same place:
def exec_cache(sql, name, binds...)
#...pseudo coded a bit but importantly
# it calls `prepare`
if !cached
stmt_key = conn.prepare(sql)
# then it calls exec_prepared
conn.exec_prepared(stmt_key, type_casted_binds)
It first has to call prepare with whatever sql we’re going to run. The caller is in charge of keeping track of whether the sql has been prepared before, otherwise Postgres will keep overwriting our previous sql and it might as well just execute an unnamed statement. Then it calls exec_prepared with only the stmt_key, which should match the name of a previously prepared query.
If we skip ahead to what gets called in libpq:
// conn.prepare(sql)
int
PQsendPrepare(PGconn *conn,
const char *stmtName,
const char *query,
int nParams,
const Oid *paramTypes) {
//...
if (pqPutMsgStart('P', conn) < 0 ||
pqPuts(stmtName, conn) < 0 ||
pqPuts(query, conn) < 0) {}
//...
}
We see something similar to our earlier Parse/Bind/Execute, but now we’re only calling the Parse portion and this time we have a stmtName. We then trigger the prepared statement calling exec_prepared, which ultimately calls PQsendQueryPrepared:
// conn.exec_prepared(stmt_key, type_casted_binds)
int
PQsendQueryPrepared(PGconn *conn,
const char *stmtName,
int nParams,
const char *const *paramValues,
const int *paramLengths,
const int *paramFormats,
int resultFormat) {
//...
return PQsendQueryGuts(conn,
NULL, // no sql
stmtName, // named
nParams,
NULL,
paramValues,
paramLengths,
paramFormats,
resultFormat);
//...
}
Anything look familiar? That’s the same PQsendQueryGuts function we called for the unnamed statement! This time it doesn’t hand a command in because we already parsed our SQL in the earlier prepare call. We also have a stmtName defined, instead of handing in an empty string. This version goes on to skip the Parse, call the Bind with the stmtName, then call Execute - same flow as our unnamed version.
For SQL injection safety, both named and unnamed versions are equivalent: they separate query structure (Parse) from data values (Bind). Adding query bindings when not in a prepared statement simply makes an unnamed statement.
Nothing about these calls is specific to the libpq library, it’s just a rock solid implementation of them13 - any language could make the same protocol calls. If a library is utilizing this protocol, they are doing the same things when binding to an unnamed prepared statement as they are when binding to a named prepared statement14.
As long as your code uses parameterized queries, “turning off” prepared statements for PgBouncer is safe, even if it seems a bit unnerving. There is a PR to allow PgBouncer to track prepared statements, so maybe this won’t cause people like me as much heartburn in the future 🥲.
Pool throughput / Long running queries 🏃♂️
We’ve got two types of connections to Postgres: active and idle. Idle connections are the backbone of poolers - having idle connections means we’ve got capacity to swap around transactions for connected clients. What about active connections?
An active connection means that connection is actively tied up by the database. For that timespan, the connection cannot be swapped out to do anything else until its operation completes. We know that active connections get expensive quickly, and we also know that most managed services range somewhere from 50 to 500 allowed total, non-pooled connections.
Using a max PgBouncer connection pool of 10k and Render’s managed Postgres service with a max of 397 total connections means we’d have:
10000 / 397 = ~25 connections per active connection
Using Supabase’s 50 connections the spread is even higher:
10000 / 50 = ~200 connections per active connection
That means that for every long running operation, you are potentially down 200 connections worth of pooling.
These numbers are very back of the napkin and of course do not represent the true scaling capability and connection handling of a real pooler. But the point is this:
- Active connections are very valuable to a pooler
- Long running queries disproportionally impact concurrency
As an example, you’re using Render Postgres fronted by PgBouncer and you’ve got 10k available connections backed by the max of 397 Postgres connections. Let’s say a new feature is introduced for populating some graph data on your app’s landing page. It’s powered by a new query that looks great, has indexes, and seems well optimized. It’s even run against some load testing and representatively sized data as a QA check. It gets deployed to production and OOF, it’s taking 15 seconds per query 🐌. Users are logging in or navigating to the landing page all the time so within moments you’ve had thousands of hits to this query. Obviously this is going to get quickly rolled back, but what does it mean for your pool in the meantime?

It means you’re maxed out. Your pooler being there means at least you’re less likely to start erroring out right away, but transaction mode can’t fix a stuck query. For each of those 15 second chunks of time your concurrency basically went from 10k back down to 397.
This is not the general behavior you’ll see when using PgBouncer unless you’ve really got some intermittent trouble with runaway queries. But it does emphasize an important point to remember: these are not real Postgres connections. Your upper bound on long running, active queries is always constrained by your actual pool of real Postgres connections.
Guarding against slow queries
- Log your slow queries using
log_min_duration_statement. This option lets you set a threshold and if queries take long than that threshold Postgres will log the offending query. This won’t help the sudden mass slow query situation mentioned above, but it helps to keep an eye on overall app query health - Use streaming queries sparingly. In most client libraries you can set your query to run in “single row mode”. This means you retrieve your rows one at a time instead of getting one big result set at once. This is helpful for efficiency with very large result sets but is slower than a full result set query, and probably means you are running queries large enough to be slower in the first place
- Use statement timeouts. This is tricky, especially when pooling, but see that section for ideas on how to approach it
- Spread out reads across read replicas
Session Level Advisory Locks 🔐
Session level advisory locks work fine in PgBouncer.

Sorry 🙈.
If you’ve read the previous sections you’ve already picked up on the pattern: “session” anything means it probably doesn’t work in transaction mode. But what does that matter to you?
Advisory locks are a great option for creating simple, cross process, cross server application mutexes based on a provided integer key. Unlike traditional locks you use/encounter elsewhere in Postgres which are tied to tables or rows, advisory locks can be created independent of tables to control application level concerns. There are plenty of other tools you could use for this job outside of Postgres, but since Postgres is already part of your tech stack it’s a convenient and simple option.
Across languages a common use case for session level advisory locks is to hold a lock while database migrations (ie, DDL) are being run. For example:
-- 1234 is arbitrary, it can be any integer
SELECT pg_advisory_lock(1234);
SET lock_timeout TO '1s';
ALTER TABLE my_table...;
INSERT INTO migrations VALUES (1234567);
-- If we don't explicitly unlock here, the lock will be held until this
-- connection is closed
SELECT pg_advisory_unlock(1234);
If another connection went to acquire the same lock, it would be blocked:
-- This will block indefinitely until the other connection is closed,
-- or calls pg_advisory_unlock(1234)
SELECT pg_advisory_lock(1234);
This is largely an attempt to improve consistency of migration tracking, and help coordinate multi process deploys:
- Continuous deployment with the potential to trigger multiple deployments in succession
- Propagating code changes to multiple servers with deploy scripts automatically triggering migrations in each context
By waiting to acquire a lock at the Postgres level, each process waits for the first lock owner to finish before continuing, coordinating each process based on a shared lock key.
Once more, with feeling PgBouncer
Now for the obligatory example of trying the same thing when connected to PgBouncer 🫠:
-- Grab the lock on connection 1
SELECT pg_advisory_lock(1234);
-- Connection 1 goes back into pool
-- ...
-- Try to unlock on connection 2, which does not own the 1234 lock
SELECT pg_advisory_unlock(1234);
-- WARNING: you don't own a lock of type ExclusiveLock
We try to unlock, but because we’re on a different connection we can’t. The lock stays locked for as long as connection 1 stays alive, which means now no one else can acquire that lock unless that connection naturally closes at some point or is explicitly pg_cancel_backended 😓.
More session advisory lock use cases
Outside of migrations, advisory locks can serve other use cases:
- Application mutexes on sensitive operations like ledger updates
- Leader election for maintaining a single but constant daemon operation across servers
- Exactly once run job controls for Postgres based job systems like GoodJob and Que
If these things sound interesting or useful, they are! But only if you connect directly to Postgres.
Transaction level locks
Advisory locks do have a transaction based companion:
-- Process 1
BEGIN;
SELECT pg_advisory_xact_lock(1234);
-- Process 2
-- Blocks while process 1 is in the transaction
SELECT pg_advisory_lock(1234);
-- Back in Process 1
SET LOCAL lock_timeout TO '1s';
ALTER TABLE my_table...;
INSERT INTO migrations VALUES (1234567);
COMMIT; -- automatically unlocks on commit or rollback
-- Process 2 now can acquire the lock
-- If you need to manually unlock while still in the transaction
-- SELECT pg_advisory_xact_unlock(1234);
You could use it as a replacement for certain scenarios, like the above migration operating transactionally. For custom purposes, it’s a good alternative!
Unfortunately most migration tooling, things like leader election, and request or job lifetime locks, all use or require a longer lived lock than a single transaction could reasonably provide.
Turn off advisory migration locks
If you need to run migrations against PgBouncer, in Rails you can turn them off with an advisory_locks flag in database.yml. Other migration tools likely have something similar. Do it at your own peril 🤷🏻♂️
Maintaining a separate direct connection to Postgres
If the lock is critical, but the operations past the lock fan out and acquire multiple connections, you could potentially have two pieces:
- A direct connection to Postgres where you acquire a session level advisory lock
- Your normal code level connection pooling using your PgBouncer connections so it can capitalize on the scaling opportunities provided there
There’s an obvious downside - you’re consuming an extra direct connection and potentially impacting throughput - but it’s an alternative available if needed.
Listen / Notify 📣
Postgres comes out of the box with a handy pub/sub feature called LISTEN/NOTIFY.
You simply call:
LISTEN channel_name;
And that connection will receive NOTIFY events:
NOTIFY channel_name, 'hi there!';
Like session level advisory locks, there are more robust pub/sub solutions out there. But the Postgres implementation works well, and you already have it available in your stack.
Looking at the example, you’ll notice that the LISTEN call is just a single statement, and it activates the listener for the current session. What have we said so many times already? Sessions bad. Transactions good… kind of.
kind of?
Similar to prepared statements, the docs are misleading when it comes to LISTEN/NOTIFY.
PgBouncer officially lists LISTEN/NOTIFY as an unsupported feature in transaction mode, which is not precisely true. LISTEN does not work in transaction mode, but NOTIFY does.
NOTIFY is a single statement, and doesn’t rely on any session semantics. It’s also transactional15:
BEGIN;
NOTIFY channel_name, 'hi!';
ROLLBACK; -- no notification is sent
Both NOTIFY formats (inside and outside a transaction) work fine with transaction mode pooling. If you want to use pub/sub, you just need to make sure your LISTENer is connected directly to Postgres. Since it can be hard to tell if you’re connected to Postgres or PgBouncer this is somewhat tricky, unfortunately.
I’ve built implementations LISTENing on a non-PgBouncer connection and NOTIFYing on PgBouncer that work fine. There’s not much writing on this, but I have found this approach to work well.
The single thread 🪡
In contrast to the multi process monster that is Postgres, PgBouncer runs on a paltry single process with a single thread.
This means that no matter how capable a server is, PgBouncer is only going to utilize a max of one CPU core so once you’ve maxed out on that core you can’t scale that single instance anymore.
A popular option is to load balance PgBouncer instances. Otherwise, almost every alternative to PgBouncer (like Odyssey, PgCat and Supavisor) utilize multiple cores.
If you’re using a managed Postgres service (like Crunchy Data, Supabase, Neon or Heroku), your default option is going with PgBouncer as a connection pooler - so it will be up to those services to offer a load balanced option.
pg_dump 🚮
If you’re running pg_dump against PgBouncer, it’s probably by mistake.
As far as I can tell, pg_dump is broken when run against PgBouncer. See https://github.com/pgbouncer/pgbouncer/issues/452.
The answer here is to make sure you’re using a direct connection to Postgres for utility operations like pg_dump.
Other unavailable features 🫥

There are some remaining features which transaction mode is incompatible with as well16. I have less or no experience with these:
WITH HOLD CURSOR- AWITH HOLDcontinues to exist outside of a transaction, which seems like it could have handy use cases but I’ve never personally used it in my day to day.- PRESERVE/DELETE ROWS temp tables - temporary tables are a session level feature so will not work properly, and preserve/delete rows are modifiers on how those temporary tables behave on commit, and are unsupported
- LOAD statement - this is for loading shared libraries into Postgres, so it makes sense this is not something you should be doing through a pooler. I haven’t actually tried, so I’m not sure if PgBouncer would stop you, but it requires super user privileges so it’s very unlikely that’s what your PgBouncer user has
PgBouncer documents a simple “SQL feature map for pooling modes” where you can see all the features mentioned in this post.
Linting 🧶
Aside from having identified potential issues - what can we do to avoid them in an automated way?
Surprisingly, not much exists. And by not much, I mean i’ve found nothing outside of advice.
It makes me feel a bit like I’m exaggerating the importance of these issues. Maybe I’m the oddball that has actually encountered many of them in real production usage and had to address them. I’ve had statement timeouts and lock timeouts misapplied. I’ve had to deal with rearranging connections because of code using a session advisory lock and LISTEN/NOTIFY, or drop libraries that use them. I’ve had to remember to turn off prepared statements in my ORM to avoid named prepared statement errors.
The implications can feel small, but they can be surprising and particularly around migrations can cause real serious downtime.
We lint everywhere. As engineers we try to automate away as many mistakes as possible with linting and specs. As development teams grow, the importance of automation becomes critical to scaling because otherwise someone somewhere is going to do the wrong thing and it won’t get caught.
Some ideas that would be great to see:
- PgBouncer optional process that detects bad queries and logs them
- RDS connection pinning behavior
- Static analysis tools for app queries
- Runtime extension to client libraries
- Making sure your development flow runs PgBouncer locally to try and encounter this behavior before running on production
In the rails world there are several active gems devoted to keeping a codebase safe from issues that would cause downtime while migrating tables (ie, zero downtime). But across ecosystems I could not find anything related to protecting against PgBouncer issues.
As a step in this direction, I’ve published a (currently experimental) gem for use in Rails/ActiveRecord apps called pg_pool_safe_query. It will log warnings if SQL is run that is incompatible with PgBouncer and raise an error if advisory locks and prepared statements are not disabled.
Can we improve connections without a pooler?
A more recent development in Postgres 14 was improvements to snapshot scalability, which seem to have resulted in big improvements in efficiently maintaining more idle connections in Postgres.
It’s exciting to see effort being applied to increasing connection efficiency in Postgres itself. The author of that snapshot scalability improvement lines up with my own frustrations:
- Ideally Postgres would better handle traffic spikes without requiring a pooler
- Poolers cut out useful database features
- Postgres itself would ideally move towards architecture changes across several key areas, eventually culminating in a larger move towards a lighter weight process/thread/async model which better aligns with the C10k problem out of the box
Most of the work in the industry seems to concentrate on building better poolers, rather than improving the internals of Postgres connection handling itself17. Outside of PgBouncer you’ve got RDS Proxy, Odyssey, PgCat, Supavisor, PgPool II and I’m sure others. All have their own benefits but suffer from the same transactional scaling limitations.
In fairness to the incredible work that goes into Postgres - every performance improvement they make in every new version is also a connection scalability improvement. If the queries, indexes, plans, and processes are making big performance gains with each version then less connections can do more.
PgBouncer alternatives
There are alternatives to PgBouncer, but the same transaction limitations apply to all of them: each has a transaction mode (or operate exclusively in transaction mode) that offers the best scaling. Once in transaction mode you can’t support most session level features anymore and you’re working off of the fact that database connections spend more time being idle than active.
They all have their own unique benefits in comparison, but have the same fundamental transaction limitations.
Am I finally done with this post?
I think I’ve said enough.
Postgres is great. PgBouncer is important. Know what can go wrong and account for it.
🐘 ✌🏼 🐘
-
This article from Brandur details some additional nuances of handling connections and pools, but these three are the higher level version of it ↩︎
-
Technically it doesn’t have to be a single instance, it could be a round Robin of multiple PgBouncers, but from a client perspective you connect to a single one
https://www.crunchydata.com/blog/postgres-at-scale-running-multiple-pgbouncers ↩︎
-
It’s even lower on their lower powered options. It goes from 20, to 120, to 400, then 500 once you’re around their $400/mo plans.
Supabase has no standard plans with more than 50 connections.
Render.com’s managed Postgres offering is based on memory available on each plan: 6 gigs or less is 97 connections, less than 10 gigs is 197 connections and over 10 gigs is 397 connections.
This isn’t totally unreasonable - managing more connections requires more cores and more memory in a process based model especially. But at their highest tiers these services don’t exceed 500 available connections.
More generalized services like Azure and Amazon RDS will let you go as high as you like, but that’ll go badly. ↩︎
-
Which is very exciting to see concentrated work on improving this aspect in Postgres internals! 🤘🏼 ↩︎
-
This more recent crunchy data article on making sure your Postgres app is production ready implies the old standard of 500 connections is no longer accurate so I’d be curious to know more specifics since most resources still emphasize these numbers https://www.crunchydata.com/blog/is-your-postgres-ready-for-production ↩︎
-
AFAIK this is largely true of any database and MySQL also has connection pooling solutions, but it does seem to be particularly necessary with postgres ↩︎
-
There are a couple caveats to this statement. Just having a dedicated low latency pool is an improvement so may slightly help concurrency. PgBouncer can also proxy multiple databases so you could increase read concurrency at least this way.
The queueing behavior of poolers can also be a benefit since you can wait for a connection to be available for longer, vs Postgres instantly rejecting the attempt: https://www.percona.com/blog/connection-queuing-in-pgbouncer-is-it-a-magical-remedy/ ↩︎
-
They do mention this in their docs:
> “Note that “transaction” pooling breaks client expectations of the server by design and can be used only if the application cooperates by not using non-working features.” ↩︎
-
https://github.com/pgbouncer/pgbouncer/issues/653
https://github.com/pgbouncer/pgbouncer/issues/249
It also just seems to be something they’re not interested in doing ↩︎
-
The idea is you fail and continue to retry. See this article for some framework agnostic approaches to retries: https://postgres.ai/blog/20210923-zero-downtime-postgres-schema-migrations-lock-timeout-and-retries ↩︎
-
I might have five nickels, but still, it happens. Also again I am grateful for anyone taking the time to write up content and share their expertise. ↩︎
-
That’s a topic for another time… ↩︎
-
In addition to the Ruby pg gem It’s used by the python psycopg lib, and node node-libpq package (and I’m sure many others). So it seems like most client libraries handle things safely enough at the protocol level to turn off prepared statements
If you are using Go with the pure Go lib/pq driver see this issue for how to properly handle unnamed statements. The rust sqlx library seems to have a similar issue. Seems that if a library does not use libpq they end up in a bit of pain when trying to work with PgBouncer ↩︎
-
Named prepared statements can boost performance for repetitious queries because they bypass the Parse call on subsequent runs. That’s their primary benefit in comparison to unnamed statements ↩︎
-
LISTENcan be called in a transaction as well, but all that means is the session level listen won’t be triggered until the transaction commits, and won’t start listening at all if a rollback is triggered ↩︎ -
I do find myself asking “what is the point of nice features if you can’t use them at scale because of transaction mode pooling”? Not being able to use certain features at scale should never preclude them from being built - but it’s a disappointing reality ↩︎
-
I’m a little afraid to have made this statement and the potential for someone to come back at me angry about this being an oversimplification 😅 ↩︎