
There is a recent language comparison repo which has been getting shared a lot. In it, CRuby was the third slowest option, only beating out R and Python.
The repo author, @BenjDicken, created a fun visualization of each language’s performance. Here’s one of the visualizations, which shows Ruby as the third slowest language benchmarked:
The code for this visualization is from https://benjdd.com/languages/, with permission from @BenjDicken
The repository describes itself as:
A repo for collaboratively building small benchmarks to compare languages.
It contains two different benchmarks:
- “Loops”, which “Emphasizes loop, conditional, and basic math performance”
- “Fibonacci”, which “Emphasizes function call overhead and recursion.”
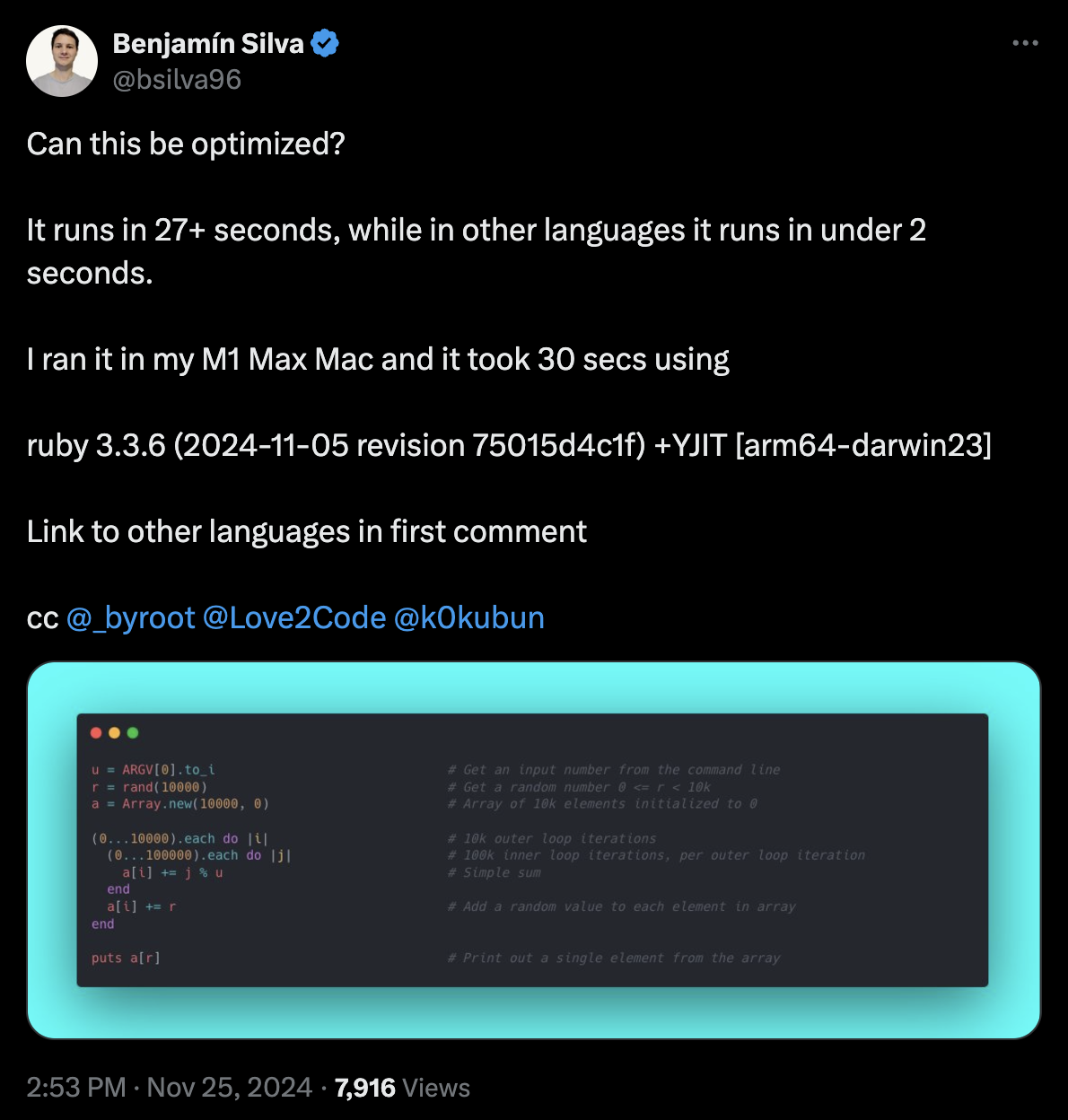
The loop example iterates 1 billion times, utilizing a nested loop:
u = ARGV[0].to_i
r = rand(10_000)
a = Array.new(10_000, 0)
(0...10_000).each do |i|
(0...100_000).each do |j|
a[i] += j % u
end
a[i] += r
end
puts a[r]
The Fibonacci example is a basic “naive” Fibonacci implementation1:
def fibonacci(n)
return 0 if n == 0
return 1 if n == 1
fibonacci(n - 1) + fibonacci(n - 2)
end
u = ARGV[0].to_i
r = 0
(1...u).each do |i|
r += fibonacci(i)
end
puts r
Run on @BenjDicken’s M3 MacBook Pro, Ruby 3.3.6 takes 28 seconds to run the loop iteration example, and 12 seconds to run the Fibonacci example. For comparison, node.js takes a little over a second for both examples - it’s not a great showing for Ruby.
| Fibonacci | Loops | |
|---|---|---|
| Ruby | 12.17s | 28.80s |
| node.js | 1.11s | 1.03s |
From this point on, I’ll use benchmarks relative to my own computer. Running the same benchmark on my M2 MacBook Air, I get 33.43 seconds for the loops and 16.33 seconds for fibonacci - even worse 🥺. Node runs a little over 1 second for fibonacci and 2 seconds for the loop example.
| Fibonacci | Loops | |
|---|---|---|
| Ruby | 16.33s | 33.43s |
| node.js | 1.36s | 2.07s |
Who cares?
In most ways, these types of benchmarks are meaningless. Python was the slowest language in the benchmark, and yet at the same time it’s the most used language on Github as of October 2024. Ruby runs some of the largest web apps in the world. I ran a benchmark recently of websocket performance between the Ruby Falcon web server and node.js, and the Ruby results were close to the node.js results. Are you doing a billion loop iterations or using web sockets?
A programming language should be reasonably efficient - after that the usefulness of the language, the type of tasks you work on, and language productivity outweigh the speed at which you can run a billion iterations of a loop, or complete an intentionally inefficient implementation of a Fibonacci method.
That said:
- The programming world loves microbenchmarks 🤷♂️
- Having a fast benchmark may not be valuable in practice but it has meaning for people’s interest in a language. Some would claim it means you’ll have an easier time scaling performance, but that’s arguable2
- It’s disappointing if your language of choice doesn’t perform well. It’s nice to be able to say “I use and enjoy this language, and it runs fast in all benchmarks!”
In the case of this Ruby benchmark, I had a feeling that YJIT wasn’t being applied in the Ruby code, so I checked the repo. Lo and behold, the command was as follows:
ruby ./code.rb 40
We know my results from earlier (33 seconds and 16 seconds). What do we get with YJIT applied?
ruby --yjit ./code.rb 40
| Fibonacci | Loops | |
|---|---|---|
| Ruby | 2.06s | 25.57s |
Nice! With YJIT, Fibonacci gets a massive boost - going from 16.88 seconds down to 2.06 seconds. It’s close to the speed of node.js at that point!
YJIT makes a more modest difference for the looping example - going from 33.43 seconds down to 25.57 seconds. Why is that?
A team effort
I wasn’t alone in trying out these code samples with YJIT. On twitter, @bsilva96 had asked the same questions:
@k0kubun came through with insights into why things were slow and ways of improving the performance:
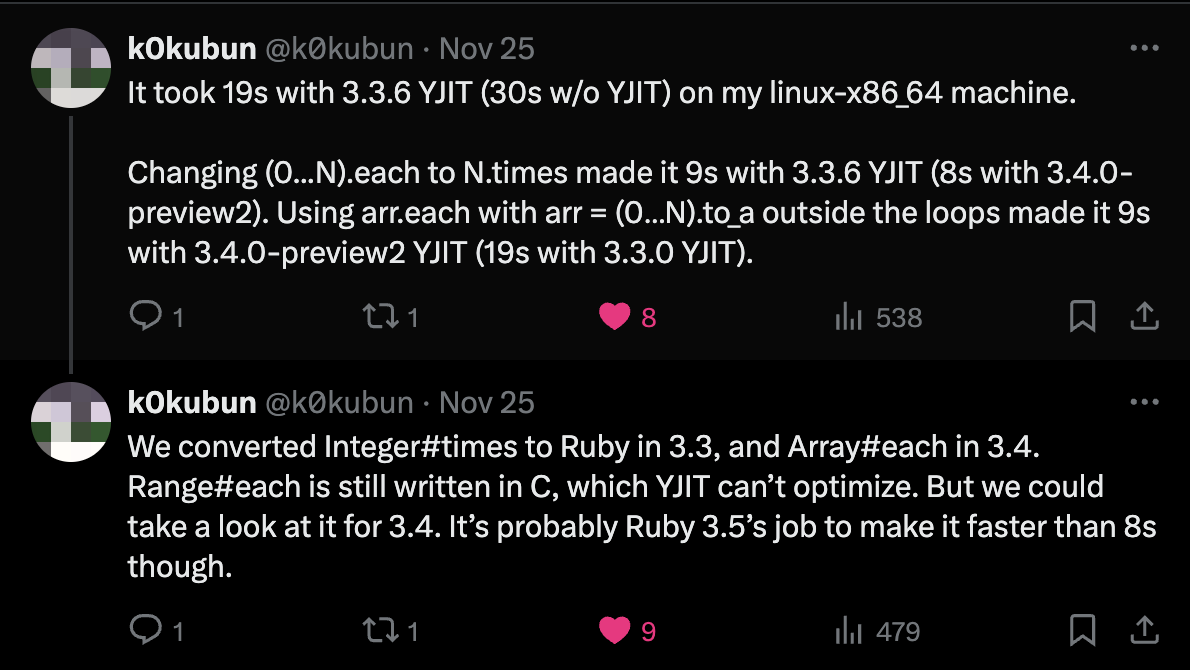
Let’s unpack his response. There are three parts to it:
Range#eachis still written in C as of Ruby 3.4Integer#timeswas converted from C to Ruby in Ruby 3.3Array#eachwas converted from C to Ruby in Ruby 3.4
1. Range#each is still written in C, which YJIT can’t optimize
Looking back at our Ruby code:
(0...10_000).each do |i|
(0...100_000).each do |j|
a[i] += j % u
end
a[i] += r
end
It’s written as a range, and range has its own each implementation, which is apparently written in C. The CRuby codebase is pretty easy to navigate - let’s find that implementation 🕵️♂️.
Most core classes in Ruby have top-level C files named after them - in this case we’ve got range.c at the root of the project. CRuby has a pretty readable interface for exposing C functions as classes and methods - there is an Init function, usually at the bottom of the file. Inside that Init our classes, modules and methods are exposed from C to Ruby. Here are the relevant pieces of Init_Range:
void
Init_Range(void)
{
//...
rb_cRange = rb_struct_define_without_accessor(
"Range", rb_cObject, range_alloc,
"begin", "end", "excl", NULL);
rb_include_module(rb_cRange, rb_mEnumerable);
// ...
rb_define_method(rb_cRange, "each", range_each, 0);
First, we define our Range class using rb_struct_define.... We name it “Range”, with a super class of Object (rb_cObject), and some initialization parameters (“begin”, “end” and whether to exclude the last value, ie the .. vs ... range syntax).
Second, we include Enumerable using rb_include_module. That gives us all the great Ruby enumeration methods like map, select, include? and a bajillion others. All you have to do is provide an each implementation and it handles the rest.
Third, we define our “each” method. It’s implemented by the range_each function in C, and takes zero explicit arguments (blocks are not considered in this count).
range_each is hefty. It’s almost 100 lines long, and specializes into several versions of itself. I’ll highlight a few, collapsed all together:
static VALUE
range_each(VALUE range)
{
//...
range_each_fixnum_endless(beg);
range_each_fixnum_loop(beg, end, range);
range_each_bignum_endless(beg);
rb_str_upto_endless_each(beg, sym_each_i, 0);
// and even more...
These C functions handle all the variations of ranges you might use in your own code:
(0...).each
(0...100).each
("a"..."z").each
# and on...
Why does it matter that Range#each is written in C? It means YJIT can’t inspect it - optimizations stop at the function call and resume when the function call returns. C functions are fast, but YJIT can take things further by creating specializations for hot paths of code. There is a great article from Aaron Patterson called Ruby Outperforms C where you can learn more about some of those specialized optimizations.
2. Optimizing our loop: Integer#times was converted from C to Ruby in Ruby 3.3
The hot path (where most of our CPU time is spent) is Range#each, which is a C function. YJIT can’t optimize C functions - they’re a black box. So what can we do?
We converted Integer#times to Ruby in 3.3
Interesting! In Ruby 3.3, Integer#times was converted from a C function to a Ruby method! Here’s the 3.3+ version - its pretty simple:
def times
#... a little C interop code
i = 0
while i < self
yield i
i = i.succ
end
self
end
Very simple. It’s just a basic while loop. Most importantly, it’s all Ruby code, which means YJIT should be able to introspect and optimize it!
An aside on Integer#succ
The slightly odd part of that code is i.succ. I’d never heard of Integer#succ, which apparently gives you the “successor” to an integer.

I’ve never seen this show, and yet it’s the first thing I thought of when I learned about this method. Thanks, advertising.
There was a PR to improve the performance of Integer#succ in early 2024, which helped me understand why anyone would ever use it:
We use Integer#succ when we rewrite loop methods in Ruby (e.g. Integer#times and Array#each) because opt_succ (i = i.succ) is faster to dispatch on the interpreter than putobject 1; opt_plus (i += 1).
Integer#succ is like a virtual machine cheat code. It takes a common operation (adding 1 to an integer) and turns it from two virtual machine operations into one. We can call disasm on the times method to see that in action:
puts RubyVM::InstructionSequence.disasm(1.method(:times))
The Integer#times method gets broken down into a lot of Ruby VM bytecode, but we only care about a few lines:
...
0025 getlocal_WC_0 i@0
0027 opt_succ <calldata!mid:succ, ARGS_SIMPLE>[CcCr]
0029 setlocal_WC_0 i@0
...
getlocal_WC_0gets ourivariable from the current scope. That’s theiini.succopt_succperforms thesucccall in ouri.succ. It will either call the actualInteger#succmethod, or an optimized C function for small numbers- In Ruby 3.4 with YJIT enabled, small numbers get optimized even further into machine code (just a note, not shown in the VM machine code)
setlocal_WC_0sets the result ofopt_succto our local variablei
If we change from i = i.succ to i += 1, we now have two VM operations take the place of opt_succ:
...
0025 getlocal_WC_0 i@0
0027 putobject_INT2FIX_1_
0028 opt_plus <calldata!mid:+, argc:1, ARGS_SIMPLE>
0029 setlocal_WC_0 i@0
...
Everything is essentially the same as before, except now we have two steps to go through instead of one:
putobject_INT2FIX_1_pushes the integer1onto the virtual machine stackopt_plusis the+in our+= 1, and calls either the Ruby+method or an optimized C function for small numbers- There is probably a YJIT optimization for
opt_plusas well
If there is nothing else to learn from this code, it’s this: the kinds of optimizations you do at the VM and JIT level are deep. When writing general Ruby programs we typically don’t and shouldn’t consider the impact of one versus two machine code instructions. But at the JIT level, on the scale of millions and billions of operations, it matters!
Back to Integer#times
Let’s try running our benchmark code again, using times! Instead of iterating over ranges, we simply iterate for 10_000 and 100_000 times:
u = ARGV[0].to_i
r = rand(10_000)
a = Array.new(10_000, 0)
10_000.times do |i|
100_000.times do |j|
a[i] += j % u
end
a[i] += r
end
puts a[r]
| Loops | |
|---|---|
| Range#each | 25.57s |
| Integer#times | 13.66s |
Nice! YJIT makes a much larger impact using Integer#times. That trims things down significantly, taking it down to 13.66 seconds on my machine. On @k0kobun’s machine it actually goes down to 9 seconds (and 8 seconds on Ruby 3.4).
It’s probably Ruby 3.5’s job to make it faster than 8s though.
We might look forward to even faster performance in Ruby 3.5. We’ll see!
3. Array#each was converted from C to Ruby in Ruby 3.4
CRuby continues to see C code rewritten in Ruby, and in Ruby 3.4 Array#each was one of those changes. Here is an example of the first attempt at implementing it:
def each
unless block_given?
return to_enum(:each) { self.length }
end
i = 0
while i < self.length
yield self[i]
i = i.succ
end
self
end
Super simple and readable! And YJIT optimizable!
Unfortunately, due to something related to CRuby internals, it contained race conditions. A later implementation landed in Ruby 3.4.
def each
Primitive.attr! :inline_block, :c_trace
unless defined?(yield)
return Primitive.cexpr! 'SIZED_ENUMERATOR(self, 0, 0, ary_enum_length)'
end
_i = 0
value = nil
while Primitive.cexpr!(%q{ ary_fetch_next(self, LOCAL_PTR(_i), LOCAL_PTR(value)) })
yield value
end
self
end
Unlike the first implementation, and unlike Integer#times, things are a bit more cryptic this time. This is definitely not pure Ruby code that anyone could be expected to write. Somehow, the Primitive module seems to allow evaluating C code from Ruby, and in doing so avoids the race conditions present in the pure Ruby solution3.
By fetching indexes and values using C code, I think it results in a more atomic operation. I have no idea why the Primitive.cexpr! is used to return the enumerator, or what value Primitive.attr! :inline_block provides. Please comment if you have insights there!
I was a little loose with my earlier Integer#times source code as well. That actually had a bit of this Primitive syntax as well. The core of the method is what we looked at, and it’s all Ruby, but the start of the method contains the same Primitive calls for :inline_block and returning the enumerator:
def times
Primitive.attr! :inline_block
unless defined?(yield)
return Primitive.cexpr! 'SIZED_ENUMERATOR(self, 0, 0, int_dotimes_size)'
end
#...
Ok - it’s more cryptic than Integer#times was, but Array#each is mostly Ruby (on Ruby 3.4+). Let’s give it a try using arrays instead of ranges or times:
u = ARGV[0].to_i
r = rand(10_000)
a = Array.new(10_000, 0)
outer = (0...10_000).to_a.freeze
inner = (0...100_000).to_a.freeze
outer.each do |i|
inner.each do |j|
a[i] += j % u
end
a[i] += r
end
puts a[r]
Despite the embedded C code, YJIT still seems capable of making some hefty performance optimizations. It’s within the same range as Integer#times!
| Loops | |
|---|---|
| Range#each | 25.57s |
| Integer#times | 13.66s |
| Array#each | 13.96s |
Microbenchmarking Ruby performance
I’ve forked the original language implementation repo, and created my own repository called “Ruby Microbench”. It takes all of the examples discussed, as well as several other forms of doing the iteration in Ruby: https://github.com/jpcamara/ruby_microbench
Here is the output of just running those using Ruby 3.4 with and without YJIT:
| fibonacci | array#each | range#each | times | for | while | loop do | |
|---|---|---|---|---|---|---|---|
| Ruby 3.4 YJIT | 2.19s | 14.02s | 26.61s | 13.12s | 14.91s | 37.10s | 13.95s |
| Ruby 3.4 | 16.49s | 34.29s | 33.88s | 33.18s | 36.32s | 37.14s | 50.65s |
I have no idea why the while loop example I wrote seems to be so slow. I’d expected it to run much faster. Maybe there’s an issue with how I wrote it - feel free to open an issue or PR if you see something wrong with my implementation. The loop do (taken from @timtilberg’s example) runs around the same speed as Integer#times - although its performance is awful with YJIT turned off.
📝 The
for inloop andarray#eachhave very similar performance, and that’s because at the Ruby VM bytecode level they are almost identical.for inis mostly syntactic sugar that transforms into an#eachcall in the VM. Thanks to Daniel Colson for pointing this out, and you can read his for loops in Ruby article for some additional information and nuance aroundfor in!
In addition to running Ruby 3.4, for fun I have it using rbenv to run:
- Ruby 3.3
- Ruby 3.3 YJIT
- Ruby 3.2
- Ruby 3.2 YJIT
- TruffleRuby 24.1
- Ruby Artichoke
- MRuby
A few of the test runs are listed here:
| fibonacci | array#each | range#each | times | for | while | loop do | |
|---|---|---|---|---|---|---|---|
| Ruby 3.4 YJIT | 2.19s | 14.02s | 26.61s | 13.12s | 14.91s | 37.10s | 13.95s |
| Ruby 3.4 | 16.49s | 34.29s | 33.88s | 33.18s | 36.32s | 37.14s | 50.65s |
| TruffleRuby 24.1 | 0.92s | 0.97s | 0.92s | 2.39s | 2.06s | 3.90s | 0.77s |
| MRuby 3.3 | 28.83s | 144.65s | 126.40s | 128.22s | 133.58s | 91.55s | 144.93s |
| Artichoke | 19.71s | 236.10s | 214.55s | 214.51s | 215.95s | 174.70s | 264.67s |
Based on that, I’ve taken the original visualization and made a Ruby specific one here just for the fibonacci run:
Speeding up range#each
Can we, the non @k0kobun’s of the world, make range#each faster? If I monkey patch the Range class with a pure-ruby implementation, things do get much faster! Here’s my implementation:
class Range
def each
beginning = self.begin
ending = self.end
i = beginning
loop do
break if i == ending
yield i
i = i.succ
end
end
end
And here is the change in performance - 2 seconds slower than times - not bad!
| Time spent | |
|---|---|
| Range#each in C | 25.57s |
| Range#each in Ruby | 16.64s |
This is obviously over-simplified. I don’t handle all of the different cases of Range, and there may be nuances I am missing. Also, most of the Ruby rewritten methods I’ve seen invoke a Primitive class for certain operations. I’d love to learn more about when and why it’s needed.
But! It goes to show the power of moving things out of C and letting YJIT optimize our code. It can improve performance in ways that would be difficult or impossible to replicate in regular C code.
YJIT standard library
Last year Aaron Patterson wrote an article called Ruby Outperforms C, in which he rewrote a C extension in Ruby for some GraphQL parsing. The Ruby code outperformed C thanks to YJIT optimizations.
This got me thinking that it would be interesting to see a kind of “YJIT standard library” emerge, where core ruby functionality run in C could be swapped out for Ruby implementations for use by people using YJIT.
As it turns out, this is almost exactly what the core YJIT team has been doing. In many cases they’ve completely removed C code, but more recently they’ve created a with_yjit block. The code will only take effect if YJIT is enabled, and otherwise the C code will run. For example, this is howArray#each is implemented:
with_yjit do
if Primitive.rb_builtin_basic_definition_p(:each)
undef :each
def each # :nodoc:
# ... we examined this code earlier ...
end
end
end
As of Ruby 3.3, YJIT can be lazily initialized. Thankfully the with_yjit code handles this - the appropriate with_yjit versions of methods will be run once YJIT is enabled:
# Uses C-builtin
[1, 2, 3].each do |i|
puts i
end
RubyVM::YJIT.enable
# Uses Ruby version, which can be YJIT optimized
[1, 2, 3].each do |i|
puts i
end
This is because with_yjit is a YJIT “hook”, which is called the moment YJIT is enabled. After being called, it is removed from the runtime using undef :with_yjit.
Investigating YJIT optimizations
We’ve looked at Ruby code. We’ve looked at C code. We’ve looked at Ruby VM bytecode. Why not take it one step deeper and look at some machine code? And maybe some Rust code? Hey - where are you going! Don’t walk away while I’m talking to you!
If you haven’t walked away, or skipped to the next section, let’s take a look at a small sliver of YJIT while we’re here!
We can see the machine code YJIT generates 😱. It’s possible by building CRuby from source with YJIT debug flags. If you’re on a Mac you can see my MacOS setup for hacking on CRuby or my docker setup for hacking on CRuby for more elaborate instructions on building Ruby. But the simplified step is when you go to ./configure Ruby, you hand in an option of --enable-yjit=dev:
./configure --enable-yjit=dev
make install
Let’s use our Integer#times example from earlier as our example Ruby code:
u = ARGV[0].to_i
r = rand(10_000)
a = Array.new(10_000, 0)
10_000.times do |i|
100_000.times do |j|
a[i] += j % u
end
a[i] += r
end
puts a[r]
Because you’ve built Ruby with YJIT in dev mode, you can hand in the --yjit-dump-disasm flag when running your ruby program:
./ruby --yjit --yjit-dump-disasm test.rb 40
Using this, we can see the machine code created. We’ll just focus in on one tiny part - the machine code equivalent of the Ruby VM bytecode we read earlier. Here is the original VM bytecode for opt_succ, which is generated when you call i.succ, the Integer#succ method:
...
0027 opt_succ <calldata!mid:succ, ARGS_SIMPLE>[CcCr]
...
And here is the machine code YJIT generates in this scenario, on my Mac M2 arm64 architecture:
# Block: times@<internal:numeric>:259
# reg_mapping: [Some(Stack(0)), None, None, None, None]
# Insn: 0027 opt_succ (stack_size: 1)
# call to Integer#succ
# guard object is fixnum
0x1096808c4: tst x1, #1
0x1096808c8: b.eq #0x109683014
0x1096808cc: nop
0x1096808d0: nop
0x1096808d4: nop
0x1096808d8: nop
0x1096808dc: nop
# Integer#succ
0x1096808e0: adds x11, x1, #2
0x1096808e4: b.vs #0x109683048
0x1096808e8: mov x1, x11
To be honest, I about 25% understand this, and 75% am combining my own logic and AI to learn it 🤫. Feel free to yell at me if I get it a little wrong, I’d love to learn more. But here’s how I break this down.
# Block: times@<internal:numeric>:259
👆🏼This roughly corresponds to the line i = i.succ in the Integer#times method in numeric.rb. I say roughly because in my current code I see that on line 258, but maybe it shows the end of the block it’s run in since YJIT compiles “blocks” of code:
256: while i < self
257: yield i
258: i = i.succ
259: end
# reg_mapping: [Some(Stack(0)), None, None, None, None]
# Insn: 0027 opt_succ (stack_size: 1)
# call to Integer#succ
👆🏼I have no idea what reg_mapping means - probably mapping how it uses a CPU register? Insn: 0027 opt_succ looks very familiar! That’s our VM bytecode! call to Integer#succ is just a helpful comment added. YJIT is capable of adding comments to the machine code. We still haven’t even left the safety of the comments 😅.
# guard object is fixnum
👆🏼This is interesting. I can find a corresponding bit of Rust code that maps directly to this. Let’s take a look at it:
fn jit_rb_int_succ(
//...
asm: &mut Assembler,
//...
) -> bool {
// Guard the receiver is fixnum
let recv_type = asm.ctx.get_opnd_type(StackOpnd(0));
let recv = asm.stack_pop(1);
if recv_type != Type::Fixnum {
asm_comment!(asm, "guard object is fixnum");
asm.test(recv, Opnd::Imm(RUBY_FIXNUM_FLAG as i64));
asm.jz(Target::side_exit(Counter::opt_succ_not_fixnum));
}
asm_comment!(asm, "Integer#succ");
let out_val = asm.add(recv, Opnd::Imm(2)); // 2 is untagged Fixnum 1
asm.jo(Target::side_exit(Counter::opt_succ_overflow));
// Push the output onto the stack
let dst = asm.stack_push(Type::Fixnum);
asm.mov(dst, out_val);
true
}
Oh nice! This is the actual YJIT Rust implementation of the opt_succ call. This is that optimization @k0kobun made to further improve opt_succ performance beyond the bytecode C function calls. We’re in the section that is checking if what we’re operating on is a Fixnum, which is a way small integers are stored internally in CRuby:
if recv_type != TypeFixnum
asm_comment!(asm, "guard object is fixnum");
asm.test(recv, Opnd::Imm(RUBY_FIXNUM_FLAG as i64));
asm.jz(Target::side_exit(Counter::opt_succ_not_fixnum));
}
That becomes this machine code:
# guard object is fixnum
0x1096808c4: tst x1, #1
0x1096808c8: b.eq #0x109683014
asm.test generates tst x1, #1, which according to an AI bot I asked is checking the least significant bit, which is a Fixnum “tag” that indicates this is a Fixnum. If it’s Fixnum, the result is 1 and b.eq is false. If it’s not a Fixnum, the result is 0 and b.eq is true and jumps away from this code.
0x1096808cc: nop
0x1096808d0: nop
0x1096808d4: nop
0x1096808d8: nop
0x1096808dc: nop
🤖 “NOPs for alignment/padding”. Thanks AI. I don’t know why it is needed, but at least I know what it probably is.
Finally, we actually add 1 to the number.
asm_comment!(asm, "Integer#succ");
let out_val = asm.add(recv, Opnd::Imm(2)); // 2 is untagged Fixnum 1
asm.jo(Target::side_exit(Counter::opt_succ_overflow));
// Push the output onto the stack
let dst = asm.stack_push(Type::Fixnum);
asm.mov(dst, out_val);
The Rust code generates our Integer#succ comment. Then, to add 1, because of the “Fixnum tag” data embedded within our integer, actually means we have to add 2 using adds x11, x1, #2 😵💫. If we overflow the space available, it exits to a different code path - b.vs is a branch on overflow. Otherwise, it stores the result with mov x1, x11!
# Integer#succ
0x1096808e0: adds x11, x1, #2
0x1096808e4: b.vs #0x109683048
0x1096808e8: mov x1, x11
😮💨. That was a lot. And it seems like alot of working is being done, but because it’s such low level machine code it’s presumably super fast. We examined a teensy tiny portion of what YJIT is capable of generating - JITs are complicated!
Thanks to @k0kobun for providing me with the commands and pointing me at the YJIT docs which contain tons of additional options as well.
The future of CRuby optimizations
The irony of language implementation is that you often work less in the language you’re implementing than you do in something lower-level - in Ruby’s case, that’s mostly C and some Rust.
With a layer like YJIT, it potentially opens up a future where more of the language becomes plain Ruby, and Ruby developer contribution is easier. Many languages have a smaller low level core, and the majority of the language is written in itself (like Java, for instance). Maybe that’s a future for CRuby, someday! Until then, keep the YJIT optimizations coming, YJIT team!
-
Naive in this case meaning that there are more efficient ways to calculate fibonacci numbers in a program ↩︎
-
MJIT, the precursor to YJIT, made Ruby much faster on certain benchmarks. But on large realistic Rails applications it actually made things slower ↩︎
-
When C code is running, it has to opt-in to releasing the GVL, so it’s more difficult for threads to corrupt or modify data mid-operation. The original Ruby version could yield the GVL at points that would invalidate the array. That’s my understanding of the situation anyways. ↩︎