
👋🏼 This is a series on concurrency, parallelism and asynchronous programming in Ruby. It’s a deep dive, so it’s divided into 12 main parts:
- Your Ruby programs are always multi-threaded: Part 1
- Your Ruby programs are always multi-threaded: Part 2
- Ruby methods are colorless
- The Thread API
- Bitmasks, Ruby Threads and Interrupts, oh my! (Concurrent, colorless Ruby)
- When good threads go bad
- Thread and its MaNy friends
- Fibers
- Processes, Ractors and alternative runtimes
- Scaling concurrency with streaming
- Abstracted, concurrent Ruby
- Closing thoughts, kicking the tires and tangents
- How I dive into CRuby concurrency
You’re reading “Your Ruby programs are always multi-threaded: Part 2”. I’ll update the links as each part is released, and include these links in each post.
- Part 1
- It’s all threaded
- Ok but how threaded is it really
- Threading mistakes
- Part 2
- Parting thoughts
- Tips for auditing gems 💎
- I use Falcon - Fibers are safe from this right?
- I use JRuby/TruffleRuby…
- Preforking / Reforking servers
- What about using mutexes for globals?
- It’s not doom and gloom, it’s detect and correct
- Takeaways 🥡
If you haven’t read “Your Ruby programs are always multi-threaded: Part 1”, you’re better off starting there. You’ll still get value of this post, but you’ll get the full context by reading both. All of the Table of Contents links under Part 1 link back to that previous article ↩️.
3b. Sharing state with fibers
Now that you’re properly clearing out thread-local state between requests/jobs, you have a new feature to write. Up until this point you could only add an image from a url - users want to upload images from their computer.
It seems complex to take a file from the front end and somehow get it to a background job. So you’re going to do it in your controller - but you want to minimize the chance of timing out while uploading a bunch of files.
📝 Since this example app is built with rails, it should instead be using ActiveStorage. But let’s just play along at home 😌
You’ve heard of an interesting library called async that makes parallelizing IO1 pretty easy and is more predictable than threads. It does it using this special Ruby 3+ FiberScheduler thing 🤔.
As a test you try uploading some files to S3 in the controller. You create an Async block, and inside of it you create as many Async blocks as there are blocking operations to parallelize:
class ImagesController
before_action :set_user
def create
Async do
params[:files].each do |file|
Async { S3Upload.new(file).call }
end
end
end
end
class S3Upload
def initialize(file)
[@file](https://micro.blog/file) = file
end
def call
object.put(body: [@file](https://micro.blog/file))
end
private
def object
client = Aws::S3::Resource.new
bucket = client.bucket(ENV["bucket"])
bucket.object(object_path(@file))
end
def object_path
[@file](https://micro.blog/file)
end
end
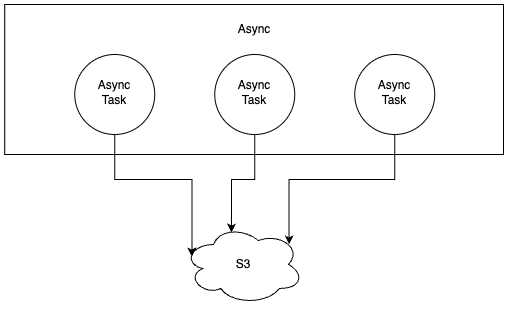
source: jpcamara.com
You test this and they all upload in parallel! Nice! Your request takes as long as the longest upload, and no longer than that. But uploading random file names at the top level of your S3 bucket is not ideal so you prefix the files with the current user id:
# ...
Async do
S3Upload.new(file, AppContext.user).call
end
# ...
class S3Upload
def initialize(file, user)
[@file](https://micro.blog/file) = file
[@user](https://micro.blog/user) = user
end
# ...
def object_path
name = [@file](https://micro.blog/file)
"#{@user.id}/#{name}"
end
end
You test this and… it raises a NoMethodError on NilClass when trying to get user.id. Huh? You’re sure the user is defined so you print some information:
class ImagesController
before_action :set_user
def create
puts "user[#{AppContext.user}]"
# ...
end
end
# ...
def object_path
name = [@file](https://micro.blog/file)
puts "upload user[#{AppContext.user}]"
puts "upload [#{@user}]"
"#{@user.id}/#{name}"
end
Which prints:
user[#<User id=123>]
upload user[]
upload [@user](https://micro.blog/user)[]
NoMethodError...
A wild Fiber appeared!
AppContext.user is nil when we’re inside that async block… I think it’s time to look at those Thread.current[] docs again…
Thread#[]
Returns the value of a fiber-local variable
Well that doesn’t seem right. Doesn’t everyone call them thread-locals? They’re not thread-local… they’re fiber-local?
What exactly does it mean for it to be fiber-local? And how can you fix it so can use your AppContext within Async?
Ruby concurrency has layers
The concurrency model in Ruby is multi-layered. The best way to describe it is as a nesting doll - as you pull away the outer layers, you find new layers of concurrency inside.
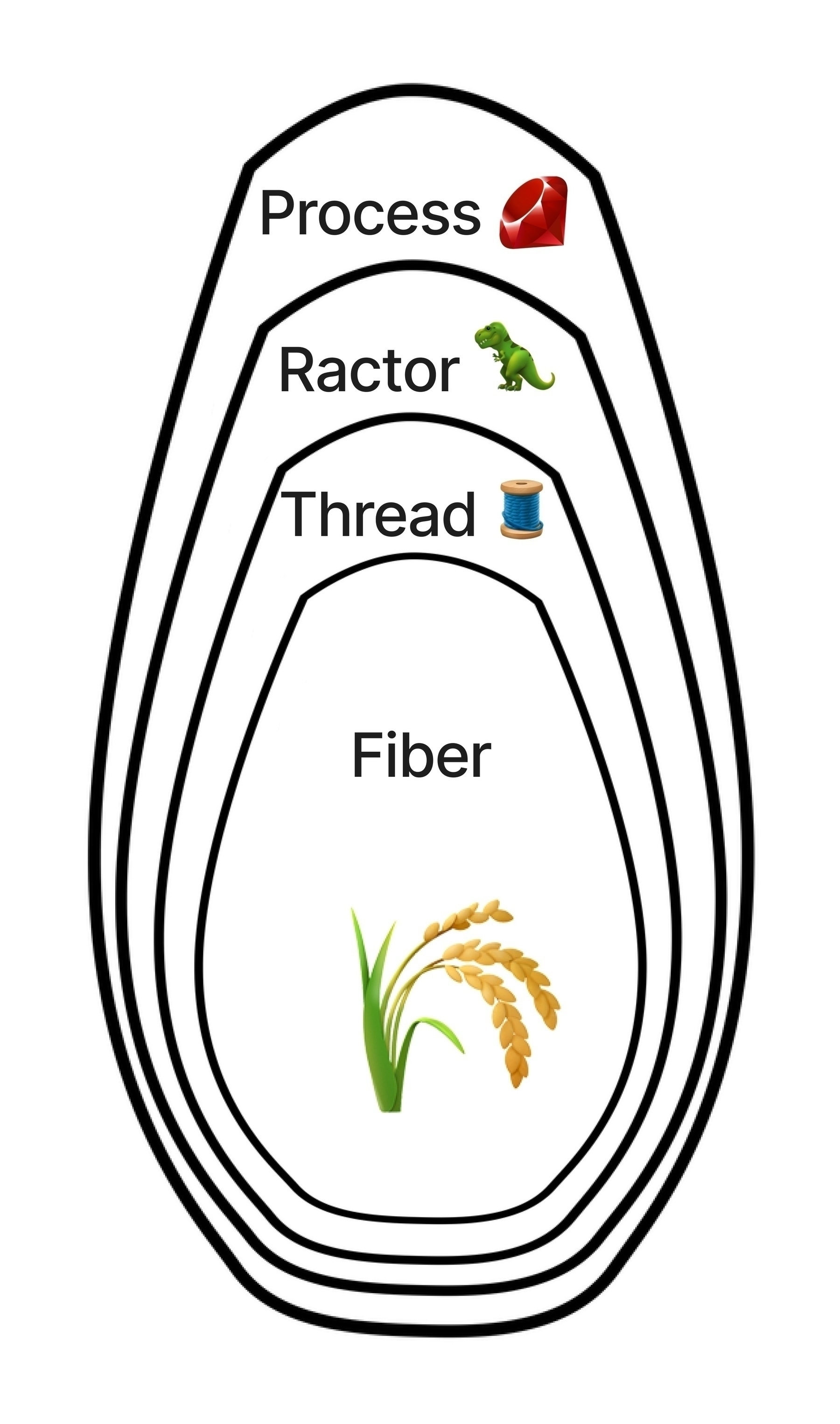
source: jpcamara.com
In your own Ruby code, you can easily inspect each layer directly:
puts "Process #{Process.pid}"
puts " Ractor #{Ractor.current}"
puts " Thread #{Thread.current}"
puts " Fiber #{Fiber.current}"
# Process 123
# Ractor #<Ractor:#1 running>
# Thread #<Thread:0x0... run>
# Fiber #<Fiber:0x0... (resumed)>
Your code is always operating in the context of a specific instance of each layer. Mostly you can access those instances with a call to current. Your code runs within a Fiber, which is inside a Thread, which is inside a Ractor, which is inside a Process. The next posts in this series will dig into every layer, but for now you’ve got a fiber problem2.
Internally, every Async block is run in a new Fiber. That’s the innermost layer of Ruby concurrency. So that means if you have something that is stored as a fiber-local, every time you create a new fiber, you get an empty, fresh set of locals.
# Fiber.current #<Fiber>
puts "Main Fiber #{Fiber.current}"
puts Thread.current[:app_user]
Fiber.new do
puts "Fiber.new #{Fiber.current}"
puts Thread.current[:app_user]
end.resume
Async do
puts "Async #{Fiber.current}"
puts Thread.current[:app_user]
Async do
puts " Async #{Fiber.current}"
puts Thread.current[:app_user]
Async do
puts " Async #{Fiber.current}"
puts Thread.current[:app_user]
end
end
end
Running the above code you get:
Main Fiber #<Fiber:0x00007a77a0b5bbb0 (resumed)>
#<User id=123>
Fiber.new #<Fiber:0x00007a77a01766b8 main.rb:940 (resumed)>
Async #<Fiber:0x00007a77a0175858 task.rb:326 (resumed)>
Async #<Fiber:0x00007a77a0174fc0 task.rb:326 (resumed)>
Async #<Fiber:0x00007a77a0174cf0 task.rb:326 (resumed)>
That’s well and good to know, you think, but how can you fix it? You don’t care about being fiber-local, you’re trying to be thread-local so these fibers can use your AppContext🧵.
Actual thread-locals
Those same Thread.current docs point us in the right direction:
For thread-local variables, see
thread_variable_getandthread_variable_set
Let’s update AppContext to use that:
class AppContext
class << self
def user
Thread.current.thread_variable_get(:app_user)
end
def user=(user)
Thread.current.thread_variable_set(:app_user, user)
self.locale = user.locale
end
def locale
Thread.current.thread_variable_get(:app_locale)
end
def locale=(locale)
Thread.current.thread_variable_set(:app_locale, locale)
end
end
end
It’s a bit more verbose, but otherwise it feels the same. Run our upload code again and…
user[#<User id=123>]
upload user[#<User id=123>]
upload [@user](https://micro.blog/user)[#<User id=123>]
Success 🙌🏼. The data is now actually thread-local. It is still present inside of fibers because those fibers all belong to the current thread3.
There are actually two more core Ruby ways4 you could handle this situation 😵💫. But we’ve covered the two most common options, and it solves the problem at hand. We’ll dig into those other options later in the series.
This seems like it should be a solved problem, you think. Does everyone write this from scratch and encounter these same issues? Is there an easier way?
Yes, thankfully.
CurrentAttributes
If you’re in Rails, or you use ActiveSupport, you should be using CurrentAttributes.
CurrentAttributes provides the same basic behavior we built (plus more), and integrates seamlessly into both Rails controllers and jobs. It also has first class support from Sidekiq, even without Rails. Here’s the AppContext code, now using CurrentAttributes:
class AppContext < ActiveSupport::CurrentAttributes
attribute :user, :locale
def user=(user)
super
self.locale = user.locale
end
end
At first glance, it’s already a much simpler and clearer setup. But the real benefit is now we don’t have to worry about anything else.
- It hooks into the Rails executor lifecycle, so whenever a web request/job begins or completes,
AppContext.resetis called - It internally uses
IsolatedExecutionState, which is an abstraction around thread and fiber-local state. It is configurable to use thread or fiber-local state, and by default it uses thread-local state so it works out of the box for your example Rails app - Sidekiq offers first class support for it, so even if you don’t use Rails you can opt-in to resetting behavior, and Sidekiq will automatically load it at the start of your job based on the execution state present when the job was enqueued
Interestingly, CurrentAttributes doesn’t use the Thread.current[] or Thread.thread_variable_get approaches. We’ll talk about that more in a later post.
RequestStore
I would not recommend using this library. It only supports Thread.current, and it only automatically clears itself for Rails controllers - you’re still on the hook for managing job middleware/callbacks! It also will fail the same way as our example in an Async block. You can learn more about it from its GitHub repository.
Back in reality, part three…
If this example seemed oddly specific again, that’s because this issue is present in some change tracking gems.
In terms of monthly downloads, paper_trail is by far the most popular gem for change tracking. And internally it uses request_store which means:
- It uses
Thread.current[] - It does take care of Rails controller cleanup for you
- it does not take care of job cleanup for you. If you set tracking information anywhere in your jobs, you are susceptible to leaking data between job runs 🙅🏻♂️.
If you’re going to use paper_trail, make sure you clear out your state in jobs. Since it uses request_store internally, you can clear out state using that.
# If using Sidekiq
class PaperTrailClearMiddleware
include Sidekiq::ServerMiddleware
def call(_worker, _job, _queue)
yield
ensure
RequestStore.clear!
end
end
Sidekiq.configure_server do |config|
config.server_middleware do |chain|
chain.add PaperTrailClearMiddleware
end
end
# If using only ActiveJob
class ApplicationJob < ActiveJob::Base
after_perform :clear_paper_trail_context
def clear_paper_trail_context
RequestStore.clear!
end
end
There is a gem that does this for Sidekiq only for you, called request_store-sidekiq. It hasn’t been updated in several years, but it does what my middleware example does, automatically for you.
All change tracking gems use some type of thread/fiber state, so here’s the rundown on the remaining popular gems:
- audited is the next most popular but it uses
CurrentAttributesinternally, so you’re good! - Logidze uses a block, so it’s basically impossible to leak data between threads. But, it uses
Thread.current[]internally so it will break if you nest fibers (likeAsyncblocks) inside of it - PublicActivity uses
Thread.current[]but it’s unclear if it is cleaning it up appropriately. You’ll have to do you own due diligence there
4. Reusing objects
You do know that single-threaded servers can still have issues leaking state between requests - like our fiber-local issue. But can they hit real threading issues? Let’s ask GitHub:
Us: Hey GitHub!
GitHub: Ummm, hi?
Us: You run Unicorn as your web server don’t you?
Github: Who are you? How did you get in here??
Us: Can a single-threaded server like Unicorn encounter threading issues?
GitHub: …
GitHub: …yes 😔 https://github.blog/2021-03-18-how-we-found-and-fixed-a-rare-race-condition-in-our-session-handling/
TL;DR
Someone wrote threaded code to save on performance:
after_action :run_expensive_op_in_thread
It held a reference to a request environment object:
def run_expensive_op_in_thread
Thread.new do
env = request.env
# some background logic
end
end
That request object got reused between requests - it just cleared its data out instead of creating a new instance:
def after_request
request.env.clear
end
In certain edge cases, sessions would get reused between users:
def run_expensive_op_in_thread
Thread.new do
if not_logged_in
login(request.env)
end
end
end
So yes… it still involved explicit threading, but in the context of a single-threaded server. This is the crux of that “Ruby is always multi-threaded” thing. Threads pop up all over the place even when you think you’re not using them. If you defensively code assuming threads could eventually be involved, you reduce the risk of these types of issues popping up later.
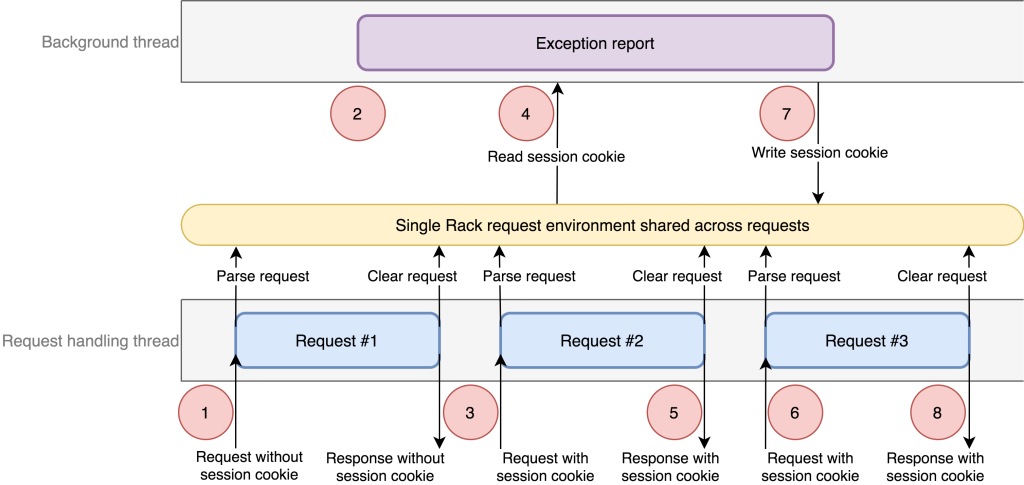
source: https://github.blog/2021-03-18-how-we-found-and-fixed-a-rare-race-condition-in-our-session-handling/
The fix for the problem was to stop reusing environment objects between requests. Each new request created a new environment object, which means a thread could safely hold onto that environment information without anything leaking in from subsequent requests.
Create new instances. Unless you know they are incredibly expensive, it is not worth the risk of sharing them if it can be avoided.
5. Race conditions
You’ve been having a tough time with these bugs, yeesh. It’s as if some kind of external force is controlling you to intentionally introduce each of these issues for other people’s benefit. But that obviously can’t be true 🤫.
You’ve got a new requirement. And this one seems pretty… concurrent. You need to coordinate some of your jobs - you split your work into several pieces, run them in individual jobs, then perform one final piece once every job has finished.
How can you coordinate a set of jobs? Maybe there’s a concurrency concept you can try out!
You read about something called a “Countdown Latch”. You tell it what to countdown from, multiple threads can safely count down using it, and you can have another thread wait until it finishes:
latch = CountdownLatch.new(10)
10.times.map do |x|
Thread.new do
puts "hello #{x}"
latch.count_down
end
end
latch.wait
puts "world!"
This prints out
hello 0
hello 1
hello 2
hello 3
hello 4
hello 5
hello 6
hello 7
hello 8
hello 9
world!
The results look ordered but it’s just a coincidence of how it ran. The
CountdownLatchonly helps coordinate completing jobs, nothing internal to their ordering
Threading concepts
When you call latch.wait, the thread waits until the count_down is complete. What would implementing a CountdownLatch look like?
class CountdownLatch
def initialize(count)
@count = count
@mutex = Mutex.new
@cond = ConditionVariable.new
puts "CountdownLatch initialized with a count of #{@count}"
end
def wait
@mutex.synchronize do
@cond.wait(@mutex) while @count > 0
end
end
def count
@mutex.synchronize { @count }
end
def count_down
@mutex.synchronize do
@count -= 1
if @count == 0
@cond.broadcast
end
@count
end
end
end
📝 The
concurrent-rubygem comes with its ownCountdownLatch. I’ve written my own here for demonstration - but if you have a need for one, use theirs, not mine
A CountdownLatch is a special form of a computer science concept called a barrier. Barriers are used to help coordinate execution of multiple threads5 - a CountdownLatch is a one-time use form of a barrier where a thread can wait until the barrier counts down to zero.
To achieve that, you need a Mutex and a ConditionVariable. Mutexs and ConditionVariables are low-level tools available for coordinating access to resources in Ruby code. We’ll dig more into those in “Concurrent, colorless Ruby”.
For now, know that a Mutex can be used to safely lock a section of Ruby code. While you are in a synchronize block, any other thread using the same Mutex will wait until that block finishes. As far as the coordinating threads are concerned, anything that happens in that block happens atomically - individual pieces which would not normally be thread-safe are treated like a single, safe operation.
Ok. We’ve got our coordinator ✅. Now let’s try applying it to our jobs.
class TickerJob
include Sidekiq::Job
def perform
# do some work
latch = CountdownLatch.new(10)
remaining = latch.count_down
puts "Tick! [#{remaining}]"
end
end
class CoordinatorJob
include Sidekiq::Job
def perform
latch = CountdownLatch.new(10)
10.times do
TickerJob.perform_async
end
latch.wait
puts "All jobs finished!"
end
end
end
end
Which gives us…!
CountdownLatch initialized with a count of 10
CountdownLatch initialized with a count of 10
Tick! [9]
CountdownLatch initialized with a count of 10
Tick! [9]
CountdownLatch initialized with a count of 10
Tick! [9]
CountdownLatch initialized with a count of 10
Tick! [9]
CountdownLatch initialized with a count of 10
Tick! [9]
CountdownLatch initialized with a count of 10
Tick! [9]
CountdownLatch initialized with a count of 10
Tick! [9]
CountdownLatch initialized with a count of 10
Tick! [9]
CountdownLatch initialized with a count of 10
Tick! [9]
CountdownLatch initialized with a count of 10
Tick! [9]
Uhhhh… hmmm… well that’s not working properly. It never finishes, and every count_down gives us 9. Oh right. You can’t create new countdowns everywhere you need them… you need to gulp… share them 😱.
You know the CountdownLatch class is thread safe, so that means multiple threads can use an instance of it together safely. You decide to use a global for now to try it out in your jobs… a class-level ivar 😅. Those are problematic, but the countdown code is thread safe so it should be ok, right? This is your time to shine!

class AppContext
def self.latch
@latch ||= CountdownLatch.new(10)
end
end
Just to be safe you try it on some simple threads first…
10.times.map do
Thread.new do
latch = AppContext.latch
# do some work
puts "Count down! [#{latch.count_down}]"
end
end
AppContext.latch.wait
CountdownLatch initialized with a count of 10
CountdownLatch initialized with a count of 10
Count down! [9]
CountdownLatch initialized with a count of 10
Count down! [9]
CountdownLatch initialized with a count of 10
Count down! [9]
CountdownLatch initialized with a count of 10
Count down! [9]
CountdownLatch initialized with a count of 10
Count down! [9]
CountdownLatch initialized with a count of 10
Count down! [9]
CountdownLatch initialized with a count of 10
Count down! [9]
CountdownLatch initialized with a count of 10
Count down! [9]
CountdownLatch initialized with a count of 10
Count down! [9]
CountdownLatch initialized with a count of 10
Count down! [9]
Well… So much for thread safety? What’s the deal?
You’re seeing CountdownLatch initialized with a count repeatedly, so it seems that the instance gets created over and over. Is the latch instance different every time?
10.times.map do |_x|
Thread.new do
latch = AppContext.latch
# do some work
puts "Count down! [#{latch.count_down}]"
puts "latch id #{latch.object_id}"
end
end
AppContext.latch.wait
🫠
...
latch id 2700
...
latch id 2720
...
latch id 2740
...
latch id 2760
...
latch id 2780
...
latch id 2800
...
latch id 2820
...
latch id 2840
...
latch id 2860
...
latch id 2880
You get a different latch every time.
Memoization / check-then-act
You’re hitting a race condition - multiple threads are racing to finish an operation. And this particular situation is so common it’s got a name: “check-then-act”.
In Ruby, the most common case of this is with memoization.
📝 If you don’t know - memoization is one of those funny looking terms, and sounds a bit like if the priest from princess bride tried to say “memorization”.

Mem-mwah-zatioooon
Memoization is just a means for lazy-loading code, or sharing an expensive resource. The first time you need it, you initialize it and store it to a variable you can reuse, like an instance variable.
Memoization is ok within a single thread, but if you’re sharing an object then memoization can lead to “check-then-act” conditions. The AppContext code is using memoization to share the CountdownLatch:
@latch ||= CountdownLatch.new(10)
It looks like a one-line call, but is actually multiple statements.
if !@latch
@latch = CountdownLatch.new(10)
end
You “check” if the @latch is present, “then” you “act” on that information. If it’s present, you don’t do anything. If it isn’t, you create a new CountdownLatch and set it to @latch. Multiple threads cannot run this code in parallel, but they can swap between each other at inopportune times.
- Thread 1 checks, and finds that
@latchisnil. It instantiatesCountdownLatchto set it to@latch. Theinitializemethod inCountdownLatchhas aputsstatement. That’s blocking IO, so Thread 1 yields and… - Thread 2 checks, and finds that
@latchisnil. As it instantiatesCountdownLatch, it yields due to the blocking IO fromputs… - Thread 3 checks, and finds that
@latchisnil… seeing a pattern?
The puts statement exists very intentionally to force this condition. Without it, the race condition would happen much less frequently. But it could be a logger call, or it could open a connection to an external resource, or create a Tempfile6. Many things can easily causes the initialize to yield to other available threads.
If you want to use memoization safely between threads, you need a Mutex. Just like CountdownLatch uses a Mutex internally to count_down safely between threads, we need a Mutex to safely share our lazy-loaded instance:
class AppContext
@latch_mutex = Mutex.new
def self.latch
return @latch if @latch
@latch_mutex.synchronize do
@latch ||= CountdownLatch.new(10)
end
end
end
💰 My personal metric is that the right amount of mutexes in my code is zero. If I am using a mutex, I think hard to figure out a way to avoid it because it means I’m opening up myself and future devs to a lot of cognitive overhead: you need to think critically anytime you make a change relating to mutex code.
If you’re a library or framework author they may be unavoidable at some point to do interesting or useful things. In my own application code, I can pretty much always avoid them.
To be perfectly honest, I’m not confident it’s ok to return the
@latchearly if it’s present. I’m pretty sure it is… but is there a memory visibility implication? Am I creating a new type of edge case or race condition? These are the questions you have to ask yourself when you introduce mutexes.
Ok, AppContex.latch memoization take three:
10.times.map do
Thread.new do
latch = AppContext.latch
# do some work
puts "Count down! [#{latch.count_down}]"
puts "latch id #{latch.object_id}"
end
end
AppContext.latch.wait
puts "All threads finished!"
Finally, you get a correct countdown!
CountdownLatch initialized with a count of 10
Count down! [9]
latch id 2700
Count down! [6]
latch id 2700
Count down! [3]
latch id 2700
Count down! [0]
latch id 2700
Count down! [7]
latch id 2700
Count down! [1]
latch id 2700
Count down! [4]
latch id 2700
Count down! [8]
latch id 2700
Count down! [5]
latch id 2700
Count down! [2]
latch id 2700
All threads finished!
Much better! We should be ready for our jobs now. But is this really the right direction? You’ve resolved the “check-then-act” issue, but you realize there are some pretty obvious limits to this approach:
- Right now we can have one instance of the
CountdownLatchto share, and it’s hard-coded to 10… What would be the best way to share an object, but also make it configurable? - What if you have more than one job server? Multiple job servers can pull jobs from the same queue 🤔. You can only synchronize across threads if they live in the same server process. Outside of that, your mutex’s ability to lock anything is just a wish in the breeze.
You need something to share, that’s independent of what’s in memory and can represent multiple coordinating sets of jobs.
read-modify-write
You’re going to branch a bit outside of threads for concurrency, and get distributed. You rewrite the CountdownLatch to:
- Allow specifying an id to key off of, so we can support more than one
CountdownLatchat a time - Store the countdown value in Redis, so it can be accessed and count down from anywhere7
- Independently create
CountdownLatchinstances so you don’t need to share the instance itself. You are sharing the Redis database instead.
class DistributedCountdownLatch
def initialize(id, count = nil)
[@id](https://micro.blog/id) = id
@redis = Redis.new
@redis.set(key, count) if count
end
def wait
while current > 0
puts "Remaining in countdown: [#{current}]"
sleep(1)
end
end
def current
@redis.get(key).to_i
end
def count_down
new_current = current - 1
@redis.set(key, new_current)
new_current
end
def key
"latch_#{@id}"
end
end
Running it across some threads looks promising.
latch = DistributedCountdownLatch.new("hello", 10)
10.times.map do |x|
Thread.new do
puts "hello #{latch.count_down}"
end
end
latch.wait
puts "world"
So far so good!
Remaining in countdown: [10]
hello 9
hello 8
hello 7
hello 6
hello 5
hello 4
hello 3
hello 2
hello 1
Remaining in countdown: [1]
hello 0
world
You run it several times and feel ready to use it in your Sidekiq jobs!
class TickerJob
include Sidekiq::Job
def perform
# do some work
latch = DistributedCountdownLatch.new("tick")
remaining = latch.count_down
puts "Tick! [#{remaining}]"
end
end
class CoordinatorJob
include Sidekiq::Job
def perform
latch = DistributedCountdownLatch.new("tick", 10)
10.times do
TickerJob.perform_async
end
latch.wait
puts "All jobs finished!"
end
end
Let’s see how it goes:
Tick! [9]
Tick! [9]
Tick! [8]
Tick! [7]
Tick! [7]
Tick! [6]
Tick! [6]
Remaining in countdown: [6]
Tick! [5]
Tick! [5]
Tick! [4]
Remaining in countdown: [4]
Remaining in countdown: [4]
Remaining in countdown: [4]
Remaining in countdown: [4]
Remaining...
Poorly. It went poorly 🥺.
If we walk through the code again:
- Thread 1 reads the value from Redis. That’s blocking IO, so Thread 1 yields and…
- Thread 2 reads the value from Redis. That’s blocking IO, so Thread 2 yields and…
- Thread 3 reads the value from Redis. That’s blocking IO, so Thread 3 yields and…
- Thread 1 gets the value back which is 10. Its subtracts 1 from it and writes 9 to Redis. That’s blocking IO, so Thread 1 yields and…
- Thread 2 gets the value back which is 10. Its subtracts 1 from it and writes 9 to Redis. That’s blocking IO, so Thread 1 yields and…
🙅🏻♂️👈🏼👉🏼👇🏼👆🏼🙅🏻♂️
You’re experiencing another race condition, and once again it’s common enough to have a name: “read-modify-write”. You’re “read”ing in a value in its current state from Redis, “modify”ing it, then “write”ing it back to Redis. The problem is that for shared resources, each reader “read”s the value in the same state. We have to coordinate the way each client is pulling data from Redis.
Race conditions happen on shared resources - those shared resources don’t need to live on the same machine.
📝 Redis is a single-threaded database, meaning it can only ever execute one thing at a time, no matter how many clients are connected. But being single-threaded does not do anything to fix race conditions. It may only execute one operation at a time, but nothing about that guarantees you won’t execute those operations out of order.
What can you do?
We need something like a Mutex, but a Mutex that can work across independent servers. A Mutex is just a lock you acquire on a resource - can you get that with Redis?
You can simulate a lock using the Redis operation SET:
class DistributedCountdownLatch
class WatchError < StandardError; end
# ... same code as before
def count_down
lock_key = "lock_#{key}"
loop do
# `nx` stands for `not exists`
# `ex` means the lock key will expire in 10 seconds
if @redis.set(lock_key, 1, nx: true, ex: 10)
new_count = current - 1
# `multi` allows every operation to run atomically
@redis.multi do |transaction|
transaction.set(key, new_count)
transaction.del(lock_key)
end
return new_count
end
sleep 0.1
end
end
end
- First you set a key using the
nx, or “not exists” flag. If a key already exists, the operation fails. In that case yousleepfor0.1seconds, then try again. - Second you get the current value.
- Third, you perform a Redis
MULTIoperation, which is a kind of Redis database transaction. We willSETthe new count, andDELete our lock key, in one atomic call to Redis. It all works, or it all fails.
📝 This type of lock is called a “Pessimistic lock”. Pessimistic locking means you must obtain exclusive access to the lock before running an operation, and retry or raise an error if that is not possible. The alternative is “optimistic” locking, which means you attempt to run the operation, and before committing verify that no other operations have taken place. If they have you either have to retry, or raise an error.
📝 If you’re going to use Redis as a distributed lock, you should use the redlock-rb gem, which implements the Redis teams recommended algorithm for locking, the “Redlock” algorithm.
By creating a simple form of a distributed Mutex, this fixes our race condition! Now we will only attempt the update once we acquire the lock, and we’ll retry until we can acquire it:
Tick! [9]
Tick! [8]
Remaining in countdown [8]
Tick! [7]
Tick! [6]
Tick! [5]
Tick! [4]
Tick! [3]
Tick! [2]
Tick! [1]
Remaining in countdown [1]
Tick! [0]
All jobs finished!
Coordinating jobs
Even having fixed the “check-then-set” and “read-modify-write” issues, trying to coordinate your jobs using this approach is a lot of work to get right. I wouldn’t recommend it, even though the code is slightly more accurate now.
If you’re interested in more appropriate ways to coordinate jobs:
- Some job servers offer a feature for running and coordinating jobs in batches, with optional success/finish/error callbacks.
- Sidekiq offers this in their paid pro tier
- GoodJob offers batch support
- I am working on batch support for SolidQueue - feel free to leave feedback!
- If you still are interested in a
CountdownLatchapproach:- Redis has a built-in
INCRandDECRmethod, which handle these updates for you atomically - ActiveRecord has an
incrementanddecrementmethod you could use todecrementa value on a record atomically.
- Redis has a built-in
read-modify-write shows up in many ways
There’s a very good chance you have code susceptible to read-modify-write issues right now. Aside from reading a value and then modifying it, the most common situation I see is around enforcing uniqueness constraints:
- You expect a record in a database to be unique, but you don’t have uniqueness constraints at the database-level.
- You “read” the database and find the record doesn’t exist.
- Another request comes in at the same time and also “read”s the database and finds the record doesn’t exist.
- In this case the “modify” is creating the record. Each request now attempts to create the record.
- With no database-level uniqueness constraint, the result is that each request thinks the record doesn’t exist, and you “write” two (or more) records, violating your uniqueness requirement.
Parting thoughts
Phew! That was a lot. We’ve gone deep into 5 different threading mistakes, ways to identify them, and ways to fix them. Let’s finish up with a few topics addressing how to look out for threading issues in your future endeavors, as well as answering some possible remaining questions!
Tips for auditing gems 💎
Here are some notes on what to look for when auditing a gem for Thread safety.
- If the gem interface is a static method, check the source. It might be an indicator of class-level ivars or thread/fiber-local data
- If the amount of code is small, take some time to understand it. Keep the “threading mistakes” we’ve discussed in mind and see if anything sticks out to you
- If there is a lot of code, look through and make sure it has active maintenance and maintainers. You’re not likely to learn a larger code base so at least know it’s being actively maintained. There have been studies to show that the longer-lived a codebase is, the likelier it is developers and users will find and remove threading issues.
- If there’s low activity, a lot of code, and you can’t take the time to understand it, you probably want to avoid it
- Make sure
mainhas been released into a gem version. The repository can sometimes be misleading - it may have a fix explaining an issue you’re hitting that hasn’t been released - If a gem is unmaintained or inactive, it doesn’t mean you can’t use it. But, effectively you own it. If you hit issues, you’ll be the one to fix them
I use Falcon - Fibers are safe from this right?
The short answer is “assume not”.
We’ll dig more into the nuances of fibers in “Concurrent, colorless Ruby: Fibers”, but you are always safer to run as if threads will eventually be involved. Falcon can run using Threads in addition to Fibers, for instance.
While Fibers are more deterministic, even with the FiberScheduler, they are still susceptible to some of the same issues as Threads.
Quick question: Can race conditions happen with Fibers? We’ll walk through that in “Concurrent, colorless Ruby: Fibers”. Or see the handy answer key below.
.seY: rewsnA
I use JRuby/TruffleRuby…
Good news! These examples will break really fast for you! Congrats!
We’ll talk more about this later in the series. But know for now that JRuby and TruffleRuby use Threads without any implicit locks (ie, the GVL). You will hit threading issues much faster in those environments than in CRuby.
Preforking / Reforking servers
Preforking and Reforking servers do share resources. They use fork, which initially shares the entire memory space between two processes using something called Copy-On-Write memory. That means things which are not safe to share, like file handles, are shared by default.
Thankfully many members of the Ruby community have worked to make that as safe as possible for most popular libraries. We’ll talk more on this topic later in the series, discussing areas where it is handled automatically and areas where it isn’t.
What about using mutexes for globals?
You may have seen some of the global examples and thought: “couldn’t you keep them global the way they are and keep them safe using a mutex?”
Good question!
That would mean using a lock to provide coordinated access to your global state. Like taking our Fibonacci example and using a lock here:
require "monitor"
class Result
attr_accessor :value
end
class Fibonacci
@fib_monitor = Monitor.new
class << self
def result=(value)
@fib_monitor.synchronize { @result = value }
end
def result
@fib_monitor.synchronize { @result }
end
def calculate(n)
@fib_monitor.synchronize do
self.result = Result.new
result.value = fib(n)
end
end
def fib(n)
return n if n <= 1
fib(n - 1) + fib(n - 2)
end
end
end
📝 We actually use a
Monitorhere instead of aMutexbecause it supports reentrancy. That means we can re-enter the synchronize block from the same thread, which is necessary in our example. Otherwise, it is largely the same as aMutex.📝 You may have noticed I removed the
attr_accessorand I both set and get using theMonitor. I did this out of caution for a concept of “visibility” of shared resources between Threads. We’ll discuss that more later.
Now we’ll run it again using run_forever:
answers = [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144]
run_forever do |iteration|
n = iteration % answers.size
Fibonacci.calculate(n)
answer = answers[n]
result = Fibonacci.result.value
if result != answer
raise "[#{result}] != [#{answer}]"
end
rescue => e
puts "Iteration[#{iteration}] #{e.message}"
end
It works. We don’t get any errors. The mutex allows the code to treat multiple operations as a single operation. Are there downsides?
- If you’re going to use a
Monitor/Mutexon a piece of a global state - keep your mutex scope small to reduce locking overhead - Don’t hog the GVL. Make sure you don’t wrap your GVL-releasing operations like blocking IO in a
Mutex. - Don’t get your mutex scope wrong. If you get your scoping wrong, you may still run into issues like memory inconsistency between Threads.
We’ll dig into GVL hogs and surprising behaviors in “Colorless, concurrent Ruby”. For now the short answer is: you can, but avoid it, if possible. It may hurt your ability to parallelize your code.
It’s not doom and gloom, it’s detect and correct
When I highlight a bunch of pitfalls you might hit, it feels like I’m being a virtual storm cloud, just trying to ruin your sunny coding day. In my post PgBouncer is useful, important, and fraught with peril, I highlight the tricky parts to inform but I still use the tool happily every day!
It’s the same for Ruby and threading concerns. Almost every language has these same problems, or worse8. Threads are easy to get wrong, so you want to take some golden paths and stay simple when using them.
Your code is safer if you assume you’re always using threads. You are. And if by some oddity you really aren’t, there’s a strong chance you will be eventually.
Takeaways 🥡
- Your Ruby code is threaded. Just assume it is and forget semantics.
- The GVL can make threading bugs harder to produce - if you see suspicious code that seems to work, try again using
run_forever - Think thread safety
- If you write any explicitly threaded code, coordinate threads or share data - use existing vetted tools like job batches and
concurrent-ruby - Other runtimes like Ruby/TruffleRuby will produce bugs much faster
- As much as possible, don’t share resources between threads. Forget your lessons from childhood: sharing is bad.
Next up
source: jpcamara.com
This is the second step into this Ruby concurrency series. Next up we’ll discuss the concept of “colorless” programming, and how it enhances the Ruby experience. We’ll also take our first dive into how the layers of Ruby work, starting with Threads.
More soon 👋🏼!
-
And any blocking operation ↩︎
-
💩 ↩︎
-
There is a short section in the thread docs that describes this behavior as well https://docs.ruby-lang.org/en/3.3/Thread.html#class-Thread-label-Fiber-local+vs.+Thread-local ↩︎
-
Fiber#storeand adding attr accessors to Thread/Fiber ↩︎ -
The concept can also be used for other units of concurrency, like fibers ↩︎
-
Or use a file mutex https://github.com/yegor256/futex ↩︎
-
Other databases would also work, but the Redis data model is the simplest to get going for a simple value. Sidekiq works off of Redis as well, so you already would have it in your stack ↩︎
-
So don’t let your Python or Java friends try to bully you about it 😉. JavaScript can suffer similar issues as well.
I’ve never supported a production Rust or Elixir application so I can’t speak from experience, but those are the only two languages I can think of that might fare a lot better in this regard (and similar languages like F#, Gleam, Clojure, etc).
Elixir because of its pure functional approach. Rust because it’s one of the first non-functional languages I’ve ever encountered that has strong consistency baked into its core. They eliminate a class of threading bugs by their nature, but can still experience issues unique to how they work. ↩︎