👋🏼 This is part of series on concurrency, parallelism and asynchronous programming in Ruby. It’s a deep dive, so it’s divided into 12 main parts:
- Your Ruby programs are always multi-threaded: Part 1
- Your Ruby programs are always multi-threaded: Part 2
- Consistent, request-local state
- Ruby methods are colorless
- The Thread API
- Bitmasks, Ruby Threads and Interrupts, oh my!
- When good threads go bad
- Thread and its MaNy friends
- Fibers
- Processes, Ractors and alternative runtimes
- Scaling concurrency with streaming
- Abstracted, concurrent Ruby
- Closing thoughts, kicking the tires and tangents
- How I dive into CRuby concurrency
You’re reading “The Thread API: Concurrent, colorless Ruby”. I’ll update the links as each part is released, and include these links in each post.
- The Thread API
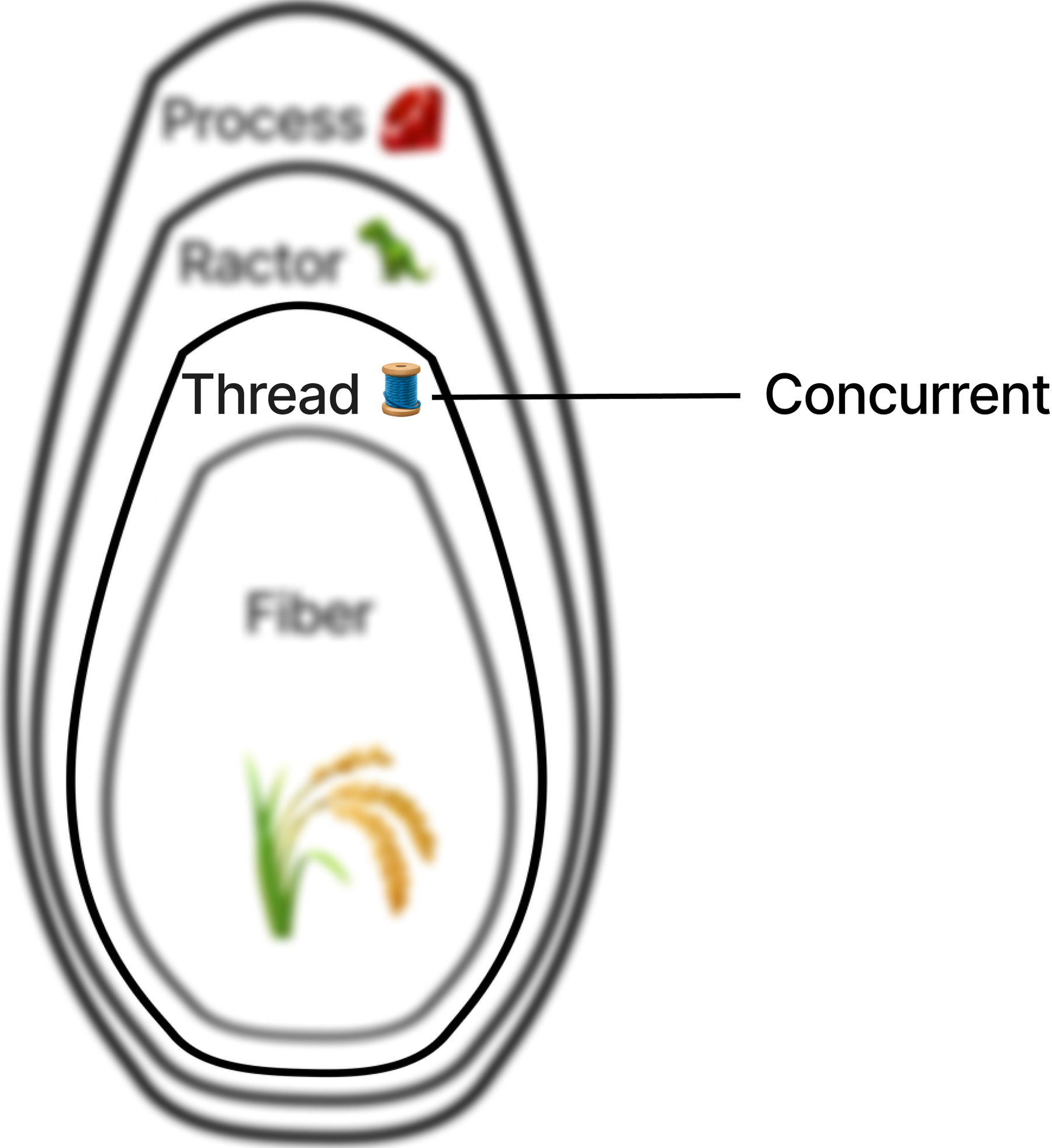
The Thread API 🧵
We’re going to break down threads into three parts:
- The Thread API - All the tools available to you in the Ruby runtime to manage threads, and how they work
- Interrupting Threads - How threads get stuck, and how to shut them down safely
- Thread and its MaNy friends - Thread architecture and the GVL
This post covers the Thread API. We’ll go over every method available to you, why they matter, how to call them, and often how popular open source projects use them.

Don’t let the cute mascot fool you
Before we start digging into threads, I’d like to make a small disclaimer: writing safe, deterministic, bug-free threaded code is hard.
I think understanding threads is valuable knowledge. After all, whether you explicitly use threads or not, your Ruby programs are always multi-threaded. If you’re always in the context of a thread, it’s helpful to know how they work behind the scenes. Even if the most you ever do is set a thread count on a server, it still helps to know how they work - it better informs what changing those numbers can and can’t do for you.
Thread.new do
puts "seems easy enough? 🤷🏻♂️"
end
Behind the simplicity of the thread interface lives a lot of complexity. An OS thread gives you the literal ability to perform tasks in parallel. And once things can run in parallel, our sequential thinking starts to fail us. It’s difficult to correctly read through code step by step if at any point that step by step code can swap out with another separate piece of code. No warning, no ability to determine exactly where your program will switch to next.
It’s the same when multiple people work on some tasks in parallel - you encounter communication breakdown. There can be contention over a shared resource. You can undo someone else’s work, or leave them with inconsistent information that causes them to finish their task, but incorrectly.

There’s a cognitive bias known as the Dunning Kruger Effect. Essentially someone with limited experience in something can overestimate their abilities, or the complexity of the task. Thread.new {} feels pretty simple - it’s easy to underestimate what goes into it. Diving into threads together helps us realize they wield a lot of power!
There’s a reason that most threaded code in gems like Rails, SolidQueue and GoodJob use the concurrent-ruby gem. Abstractions are your friend. We’ll dig into abstractions later in the series - for now we’ll learn about threads directly. But dont stop here! Learn the foundation, and when you need it yourself, learn the abstractions and tools that make it easier.
source: Eli and JP Camara, https://x.com/logicalcomic
This post will dig into all the options available in Ruby out of the box. You’ll learn each thread method and what they’re for, and we’ll discuss how to coordinate your threads once you create them. Let’s go!
A thread api primer (with examples!)
We’ll start off with some details on how you interact with threads. Let’s create a thread!
Thread.new do
sleep 10
puts "finished!"
end
Run that code1 👆🏼… hmmm, nothing happens. Nothing prints and the program exits silently. What happened?
Everything starts off running in the “main thread”, which is accessible by calling Thread.main. When a new thread is created it’s like a branch off of the main thread. Those branches exist independently and the main thread doesn’t wait for them to finish by default.
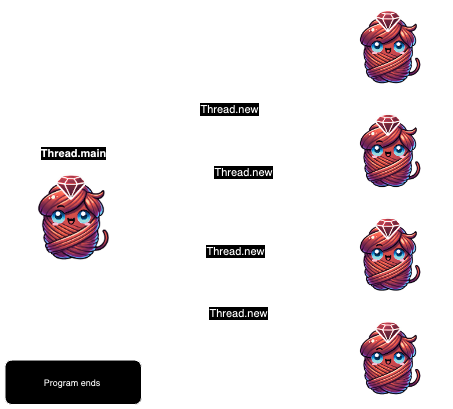
Waiting for a thread to complete
join
To wait on a specific thread, you join that thread and the current thread together. Here we have the main thread join with t:
t = Thread.new do
sleep 10
puts "finished!"
end
# We're at the top level in `Thread.main`, which "joins" with `t` until it finishes
t.join
# finished!
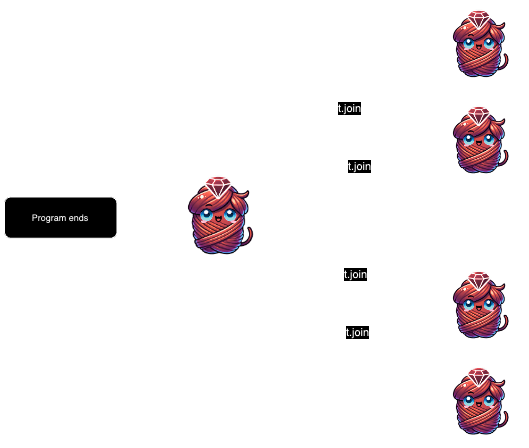
When the thread finishes, the thread object is returned from join.
———
value
You can also join on a thread and ask it for the last value returned using value:
t = Thread.new do
sleep 10
File.read(a_file_path)
end
puts t.value # contents of `a_file_path`
The simplest way to run some work concurrently is to start up several threads and then iterate over each one calling join or value. We’ll make 4 http requests here, and the overall time will take as long as the longest request:
# frozen_string_literal: true
require "net/http"
require "json"
def generate_uuid_thread
url = "https://httpbin.org/uuid"
Thread.new do
response = Net::HTTP.get(URI(url))
JSON.parse(response)["uuid"]
end
end
uuids = 4.times.map do
generate_uuid_thread
end.map(&:value)
puts uuids
# 6b76167d-9bac-45dc-8d0b-5b7af865b843
# a025a125-51a5-4773-b78d-ab93fba02eb3
# 98befb95-adf7-4c89-9fd0-d10f6b2a3d7a
# 95f486fd-5bc6-46fe-b65a-c52a87140dfb
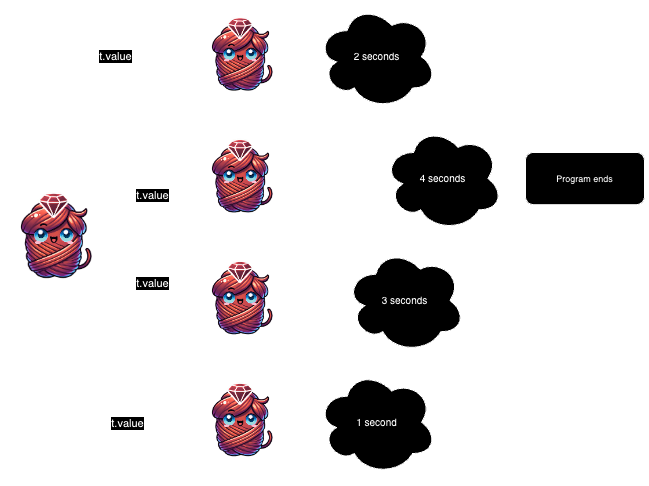
Make sure you let each thread start first! If you join too early, you end up running them sequentially:
uuids = []
uuids << generate_uuid_thread.value
uuids << generate_uuid_thread.value
uuids << generate_uuid_thread.value
uuids << generate_uuid_thread.value
puts uuids
# 6b76167d-9bac-45dc-8d0b-5b7af865b843
# a025a125-51a5-4773-b78d-ab93fba02eb3
# 98befb95-adf7-4c89-9fd0-d10f6b2a3d7a
# 95f486fd-5bc6-46fe-b65a-c52a87140dfb
The end result looks identical, and the output is but the execution is totally different. When we create all the threads up front, certain operations can run in parallel:
- Threads 1 through 4 get created and are “runnable”
- The main thread blocks on the first iteration to call
map(&:join) - As each thread blocks on the HTTP call, they run in parallel
- The loop takes as long as the longest thread, so if it takes us 50ms for 3 requests, and the 4th is 100ms, we spend around 100ms total
Calling generate_uuid_thread.value one at a time, we’re just running the code sequentially:
- Thread 1 gets created and run, returning its
value - Thread 2 gets created and run, returning its
value - Same for threads 3 and 4
- We’re running sequentially, so the threads provided no value. It would take roughly 250ms. If anything, the threads likely added overhead.
⚠️ Never actually generate a uuid using a web service, that’s crazy 🤣
———
join(timeout_in_seconds)
You can also limit the amount of time you join. If you’re calling join, typically you just want to wait however long it takes. But using join(seconds) could be useful to periodically pop into some other work or alert that you’ve been running too long. join(seconds) will return the thread while it is still running, and return nil once it finishes.
t = Thread.new do
sleep 10
end
t2 = Thread.new do
sleep 20
end
while t2.alive?
puts "wait a bit more... #{t2.join(5)}"
end
puts "done!"
# wait a bit more...
# wait a bit more...
# wait a bit more...
# wait a bit more... #<Thread:0x0... main.rb:116 dead>
# done!
def fib(n)
return n if n <= 1
fib(n - 1) + fib(n - 2)
end
t2 = Thread.new do
fib(40)
end
while t2.alive?
puts "wait a bit more... #{t2.join(0.01)}"
end
puts "done! #{t2.value}" # get returned even after a join
# wait a bit more...
# wait a bit more...
# wait a bit more...
# wait a bit more...
# wait a bit more...
# done! 9227465
You could use it to intermittently check for a thread finishing without wasting too many CPU cycles:
t = Thread.new do
sleep 5
end
while t.join(1)
puts "still waiting..."
end
puts "done!"
# still waiting...
# still waiting...
# still waiting...
# still waiting...
# done!
In the Puma web server, it uses join(seconds) to manage shutting down its thread pool. It iterates over each thread, adjusting the join timeout based on how much time has elapsed since starting the method:
join = ->(inner_timeout) do
start = Process.clock_gettime(
Process::CLOCK_MONOTONIC
)
threads.reject! do |t|
elapsed = Process.clock_gettime(
Process::CLOCK_MONOTONIC
) - start
t.join inner_timeout - elapsed
end
end
# Wait +timeout+ seconds for threads to finish.
join.call(timeout)
It uses join(timeout) to try and let each thread finish before forcing a shutdown with raise or kill. The reject! removes any threads that finish during that time - nil returned from join means the thread is still running, otherwise the thread object is returned (removing it from the array).
📝 A “thread pool” is a reusable, typically fixed size set of threads. Rather than create brand new threads every time they are needed, a thread pool saves on thread creation by reusing threads to perform operations. They are generally used to save on thread creation cost and limit the number of threads running at a time.
concurrent-rubycomes with several types of thread pools.
Error Reporting
report_on_exception and abort_on_exception
What happens if something fails in your thread?
t = Thread.new do
raise "oops!"
end
sleep # does the program sleep forever, or raise an error?
Running that 👆🏼, it just runs forever. Even though our thread has failed, it never impacts the program. We will see an error printed in our console, however:
terminated with exception (report_on_exception is true):
main.rb:2:in `block in <main>`: oops! (RuntimeError)
You can control whether it fails silently, but the default is to report the error. Keep that default - silent errors are not your friend. But if you really needed to, you can change it globally or with a per thread setting:
# No threads log their errors ☠️
Thread.report_on_exception = false
# This individual thread does not log
t.report_on_exception = true
What if you want to report it in the current thread? Similar to joining execution with a thread to wait for it to finish, you need to join with it to raise its error:
t = Thread.new do
raise "oops!"
end
t.join # or .value, raises "oops!"
You can also force the thread to raise, even when running independently:
t = Thread.new do
sleep 5
raise "listen to me!"
end
t.abort_on_exception = true
sleep 10 # t blows up the program!
This can be set globally as well:
Thread.abort_on_exception = true
t = Thread.new do
sleep 5
raise "listen to me!"
end
sleep 10 # t blows up the program!
Rack timeout uses it in its Scheduler thread, applying it using Thread.current:
def run_loop!
Thread.current.abort_on_exception = true
In general, you don’t see this much in a production setting. But it could be useful if you’re writing a one-off script and you want any thread that fails to kill the program.
Tracking threads
Can we find out what threads are running?
Thread.list
Thread.list will give you every thread that hasn’t already finished:
Thread.new { sleep 0.1 }
Thread.new { sleep 0.1 }
Thread.new { sleep 0.1 }
Thread.new {}
puts Thread.list
#<Thread:0x0... run>
#<Thread:0x0... main.rb:1 sleep>
#<Thread:0x0... main.rb:2 sleep>
#<Thread:0x0... main.rb:3 sleep>
#<Thread:0x0... main.rb:4 dead>
name
Ok… but how can you differentiate them? There’s a few ways you can achieve that:
- File information
- Setting a name
- Inheritance
File information gets printed by default, and shows you the name of the file and what line the thread was started on:
t = Thread.new { sleep 0.1 }
t2 = Thread.new { sleep 0.1 }
t3 = Thread.new { sleep 0.1 }
t4 = Thread.new { sleep 0.1 }
puts Thread.list
#<Thread:0x0...main.rb:1 sleep>
#<Thread:0x0...main.rb:2 sleep>
#<Thread:0x0...main.rb:3 sleep>
#<Thread:0x0...main.rb:4 sleep>
The file info is useful, but often your threads are all started from the same place, so it doesn’t tell you much:
def start_thread
Thread.new { sleep 0.1 }
end
t = start_thread
t2 = start_thread
t3 = start_thread
t4 = start_thread
puts Thread.list
#<Thread:0x0...main.rb:2 sleep>
#<Thread:0x0...main.rb:2 sleep>
#<Thread:0x0...main.rb:2 sleep>
#<Thread:0x0...main.rb:2 sleep>
In that case, you can set a name on each thread to differentiate them:
Thread.main.name = "main"
t.name = "first!"
t2.name = "second!"
t3.name = "third!"
t4.name = "fourth!"
puts Thread.list
#<Thread:0x0...@first! main.rb:2 sleep>
#<Thread:0x0...@second! main.rb:2 sleep>
#<Thread:0x0...@third! main.rb:2 sleep>
#<Thread:0x0...@fourth! main.rb:2 sleep>
The concurrent-ruby gem uses this to help differentiate threads created in its ThreadPoolExecutor:
# concurrent/executor/ruby_thread_pool_executor.rb
[@thread.name](http://thread.name) = [pool.name, 'worker', id].compact.join('-')
#...
require "concurrent"
pool = Concurrent::ThreadPoolExecutor.new(
name: "🤖"
)
pool.post { sleep 0.1 }
pool.post { sleep 0.1 }
pool.post { sleep 0.1 }
pool.post { sleep 0.1 }
puts Thread.list
#<Thread:0x0...@🤖-worker-1...concurrent/executor/ruby_thread_pool_executor.rb:339 sleep_forever>
#<Thread:0x0...@🤖-worker-2...concurrent/executor/ruby_thread_pool_executor.rb:339 sleep_forever>
#<Thread:0x0...@🤖-worker-3...concurrent/executor/ruby_thread_pool_executor.rb:339 sleep_forever>
#<Thread:0x0...@🤖-worker-4...concurrent/executor/ruby_thread_pool_executor.rb:339 sleep_forever>
The Honeybadger gem runs a background thread when sending errors to their error reporting service. To differentiate their thread, they use inheritance. The information about each thread includes the class so it makes it easy to identify:
module Honeybadger
class Worker
class Thread < ::Thread; end
end
end
Honeybadger::Worker::Thread.new { sleep 0.1 }
puts Thread.list
#<Thread:0x0... run>
#<Honeybadger::Worker::Thread:0x0... main.rb:119 sleep>
———
status, alive? and stop?
Can you keep track of the status of a running thread? Yep! Threads operate in one of 5 states - they’re not the most intuitive, but they’re what you’ve got:
“run”- the thread is running“sleep”- the thread is “sleeping”. There is some blocking operation going on or the thread went to sleep or was put to sleep by the thread scheduler“aborting”- the thread has failed but hasn’t finished running yetnil- an error was raised and the thread is deadfalse- the thread finished normally
Let’s demonstrate some statuses:
a = Thread.new { raise("bye bye") }
b = Thread.new { Thread.stop }
c = Thread.new {}
d = Thread.new {
IO.select(nil, nil, nil, 3)
}
d.join(1) # wait on d for 1 second
puts a.status.class #=> NilClass
puts b.status #=> "sleep"
puts c.status #=> false
puts d.status #=> "sleep"
puts Thread.current.status #=> "run"
You’ll notice a few things about the above:
- I didn’t show “aborting”. That’s because I’m not sure regular code could ever see that status. Catching a failed thread that hasn’t finished yet seems pretty hard to do. Internally the CRuby thread needs to be in a
to_killstate. I would love it if someone knows a way to demonstrate it, though! It would perhaps require the assistance of a core CRuby wizard 🧙♀️. - “sleep” is not specific to the
sleepmethod. In threaddwe are making anIO.selectcall that takes three seconds. So the thread blocks while waiting, hence it is “sleep”ing. - Since you can’t run Ruby code in multiple threads in parallel, you pretty much would only ever see “run” on the current, active thread.
It would be nice if the information was a bit more readable. We can put together a little helper to make the output clearer. We’ll also add in one more internal status not directly exposed by status:
ThreadStatus = Data.define(
:status, :error
)
def thread_status(thread)
error = nil
status = case thread.status
when NilClass
error = begin
thread.join
rescue => e
e
end
"failed w/ error: #{error}"
when FalseClass then "finished"
when "run" then "running"
when "sleep"
parse_thread_sleep_status(thread)
else thread.status
end
ThreadStatus.new(status:, error:)
end
def parse_thread_sleep_status(thread)
status = thread.to_s
status[status.index("sleep")..-2].sub(
"sleep", "sleeping"
)
end
# our previous thread code... then...
puts thread_status(a)
puts thread_status(b)
puts thread_status(c)
puts thread_status(d)
puts thread_status(Thread.current)
#<ThreadStatus status="failed w/ error: bye bye", error=#<RuntimeError: bye bye>
#<ThreadStatus status="sleeping_forever", error=nil>
#<ThreadStatus status="finished", error=nil>
#<ThreadStatus status="sleeping", error=nil>
#<ThreadStatus status="running", error=nil>
Using our new helper, we get a bit more readability and depth into our thread statuses.
- Using
joinwe are able to return more information about the failed thread - “failed” instead of nil, and the actual error it failed with - We return “finished” instead of false for a successful finish
sleep_foreverlet’s us differentiate actively blocked threads (like one doingIO.select) from a thread that is actually stopped, and won’t run again without intervention. We’ll talk more aboutThread.stopin the next section
In addition to status, we can also use alive? and stop? to check on a threads status:
t = Thread.new {}
t2 = Thread.new { loop {} }
t3 = Thread.new { Thread.stop }
t.name = "quick"
t2.name = "slow"
t3.name = "on ice"
[t, t2, t3].each do |thread|
# make sure it gets a chance to run
thread.join(0.01)
puts "#{thread.name}: " \
"alive? #{thread.alive?}, " \
"stopped? #{thread.stop?}"
end
# quick: alive? false, stopped? true
# slow: alive? true, stopped? false
# on ice: alive? true, stopped? true
Thread Scheduling
There are several methods for either taking direct action, or suggesting action to the thread scheduler. Before using them, keep in mind that you’re probably not smarter than the Ruby thread scheduler. It tries to do what makes the most sense for the runtime, and it’s been tuned extensively. But these tools exist, and they get used, so let’s discuss them a bit.
Thread.pass, wakeup, Thread.stop, run, and priority
pass and wakeup are kind of like nudges to the runtime. They request a particular action, but the scheduler does not have to honor them. Thread.pass tells the thread scheduler it can “pass” control to another thread:
t = Thread.new do
Thread.pass
puts "hi!"
end
t2 = Thread.new do
puts "bye!"
end
t.join
t2.join
# Most of the time you will see:
# bye!
# hi!
# but it's not guaranteed
wakeup marks a thread as eligible for scheduling. It’s up to the thread scheduler whether that happens:
t = Thread.new do
Thread.stop
puts "hi!"
end
t.join(1)
t.wakeup
t.join
# hi!
Thread.stop and run are more direct commands to the thread scheduler:
t = Thread.new do
now = Time.now
sleep 10
puts "Seconds slept: #{Time.now - now}"
end
t.join(1)
t.run
t.join
# Seconds slept: 1.000076481
Only one second has passed, but run caused the sleep to finish early.
t = Thread.new do
Thread.stop
puts "done!"
end
t.join(0.1)
puts thread_status(t)
puts "alive? #{t.alive?}"
puts "stopped? #{t.stop?}"
t.run
t.join
#<ThreadStatus status="sleeping_forever">
# alive? true
# stopped? true
# done!
priority gives a hint to the scheduler of which thread should be given more runtime. The thread docs have a good example of this:
count1 = count2 = 0
a = Thread.new do
loop { count1 += 1 }
end
a.priority = -1
b = Thread.new do
loop { count2 += 1 }
end
b.priority = -2
sleep 1
puts count1 #=> 21472634
puts count2 #=> 14256235
The threads run forever, but thread a gets higher priority so it adds to the counter more often.
For an open source example of run, you can check the rack-timeout scheduler:
def schedule(event)
@mx_events.synchronize {
@events << event
}
runner.run # wakes up the runner thread so it can recalculate sleep length taking this new event into consideration
return event
end
Thread.pass is a recommendation from Mike Perham if you have your jobs hogging CPU:
class ExpensiveJob
include Sidekiq::Job
def perform
loop do
# expensive stuff
Thread.pass if occasional_condition
end
end
end
Thread Shutdown
raise and kill
You want to kill… me? 🥺
⚠️ TL;DR You shouldn’t use these methods unless you really know what you’re doing. Instead, interrupt your thread safely. Incidentally, you should also avoid the timeout module. We’ll dig deep into raise and kill in the next post on “Interrupting Threads”.
Interrupt your thread safely
Instead of killing your thread, set it up to be interruptible. Most mature, threaded frameworks operate this way.
still_kickin = Concurrent::AtomicBoolean.new(true)
Thread.new do
while still_kickin.true?
# more work!
end
end
still_kickin.make_false
Don’t use timeout
If you see this in code, be concerned:
require "timeout"
Timeout.timeout(1) do
# 😱
end
For some reason, the timeout gem itself doesn’t warn about any issues. But Mike Perham summarizes it best:

There’s nothing that exactly matches what timeout offers: a blanket way of timing out any operation after the specified time limit. But instead of using the timeout gem, there is a repository called The Ultimate Guide to Ruby Timeouts. It shows you how to set timeouts safely for basically every blocking operation you could care about timing out. For instance, how to properly handle timeouts using the redis gem:
Redis.new(
connect_timeout: 1,
timeout: 1,
#...
)
The one piece mentioned in that repository you should leave alone: Net::HTTP open_timeout. Behind the scenes it uses the timeout module 🙅♂️. Leave the 60 second default, it should almost never impact you, and you’re probably worse off lowering it.
———
Thread.handle_interrupt
A thread can be externally “interrupted” by a few things:
Thread#killThread#raise- Your program being exited
- A signal, like Ctrl+C
handle_interrupt gives you the ability to control how your program reacts to 1-32.
Because it primarily matters in the context of raise and kill, we’ll discuss it in the next post on “Interrupting Threads”.
———
Process._fork
Process#_fork isn’t a thread api, but it’s good be aware of for your threaded code.
What’s happens to a thread when a process forks?
t = Thread.new { sleep }
fork do
puts "inside fork: #{thread_status(t)}"
end
puts "outside fork: #{thread_status(t)}"
# outside fork: #<ThreadStatus status="running">, pid: 362
# inside fork: #<ThreadStatus status="finished">, pid: 367
You can’t bring your threads with you when you fork. But you can recreate them, using _fork!
module OnFork
def _fork
pid = super
if pid == 0
# your code to restart threads
end
pid
end
end
Process.singleton_class.prepend(OnFork)
It’s a little strange of a setup. You’re hooking into the inheritance chain for Process._fork, so you need to call super directly. No one calls _fork directly, super ultimately returns the result of fork itself. If the result is 0, we’re in the forked process, which means we can perform any kind of post-fork action. In the case of managing threads, that would involve recreating them.
The connection_pool gem uses this to run an after_fork method. It uses it to close out connections.
module ForkTracker
def _fork
pid = super
if pid == 0
ConnectionPool.after_fork
end
pid
end
end
Process.singleton_class.prepend(
ForkTracker
)
The redis-client gem uses _fork to track the pid in PIDCache, so it can determine whether it needs to close the inherited socket (threads are not inherited when forking, but file descriptors are).
def ensure_connected(retryable: true)
close if !config.inherit_socket && @pid != PIDCache.pid
Coordinating Threads
Now that we know the different methods of interacting with a thread directly, how can we coordinate threads together safely?
📝 If you can avoid it, don’t coordinate at all! Immutable structures, or isolated work are your friends.
Mutex
Mutex is the core thread coordination primitive in Ruby. It stands for mutual exclusion, and it allows you to control single thread access to a particular resource. A thread or fiber acquires a lock on the mutex, and it is the only thing that can unlock that mutex.
📝 If you know database locks, a
Mutexbasically operates like an exclusive lock.
📝 You’re better off not sharing objects, it keeps things simpler. I’ll reference my own note from “Your Ruby programs are always multi-threaded: Part 2”:
My personal metric is that the right amount of mutexes in my code is zero. If I am using a mutex, I think hard to figure out a way to avoid it because it means I’m opening up myself and future devs to a lot of cognitive overhead: you need to think critically anytime you make a change relating to mutex code.
If you’re a library or framework author they may be unavoidable at some point to do interesting or useful things. In my own application code, I can pretty much always avoid them.
Earlier we used a class from concurrent-ruby called AtomicBoolean to implement an interruptible thread. What if we wanted to implement it ourselves?
class AtomicBoolean
def initialize(default = false)
@value = default
@mutex = Mutex.new
end
def true?
@mutex.synchronize { value == true }
end
def false?
@mutex.synchronize { value == false }
end
def make_true
@mutex.synchronize { @value = true }
end
def make_false
@mutex.synchronize { @value = false }
end
end
To make sure our data stays consistent, we synchronize every access. That way we know we can’t corrupt anything and we have a consistent view of ``@value```:
still_kickin = AtomicBoolean.new(true)
Thread.new do
while still_kickin.true?
# more work!
end
end
still_kickin.make_false
It doesn’t make sure we do things in any expected order, but it’s a foolproof way of having proper access and visibility.
📝 Truthfully, CRuby doesn’t need this kind of corruption guarantee. But true parallel Ruby runtimes like JRuby and TruffleRuby do.
synchronize is the probably the only method you’ll find yourself using on a Mutex. Look in different projects and that’s 95% of all Mutex usage. But there are more methods available you may see on occasion:
lockunlocktry_lockowned?locked?sleep
lock and unlock can be used to recreate what synchronize does:
def synchronize(mutex)
mutex.lock
yield
ensure
mutex.unlock
end
synchronize(mutex) do
# locked work
end

try_lock lets you attempt a lock without blocking. When you call lock or synchronize, your code will block until you are able to acquire a lock:
mutex = Mutex.new
t = Thread.new do
mutex.lock
loop {} # runs forever, never releasing
ensure
mutex.unlock
end
t2 = Thread.new do
mutex.synchronize do
# do some work
end
end
t.join(1)
t2.join # t never releases the lock, so t2 runs forever
But try_lock will just return a boolean if the lock worked:
mutex = Mutex.new
t = Thread.new { mutex.lock; loop {} }
t2 = Thread.new do
if mutex.try_lock
# do some work
else
raise "Couldn't acquire the lock!"
end
ensure
mutex.unlock if mutex.owned?
end
t.join(1)
t2.join # tries to acquire the lock, and raises an error because it can't
Notice the owned? call in the ensure? We don’t know if the lock was successfully acquired, so we only call unlock if the lock is owned?. Being owned? means the current thread successfully acquired the lock, and is the current “owner”. If you tried to call unlock on a thread that wasn’t the owner, an error would be raised.
locked? allows you to check if the lock is owned by some thread. Seems susceptible to some race conditions, but you could use it to determine if you need to perform an action. The aws-sdk-core uses it to determine whether to create a thread for an “async refresh”. If the thread has already started and is refreshing, locked? will be true and no thread will be created:
unless @mutex.locked?
Thread.new do
@mutex.synchronize do
# refresh async
end
end
end
Last we have sleep(timeout = nil), which releases the lock for timeout seconds, or runs forever if given nil. This is exactly what the rack-timeout gem uses internally to create a Scheduler class which it uses to schedule request timeouts:
def initialize
@mx_events = Mutex.new
# ...
end
def run_loop!
loop do # begin event reader loop
@mx_events.synchronize {
@events.reject!(&:cancelled?)
sleep_for = [@events.map](http://events.map)(&:monotime).min
@mx_events.sleep sleep_for
It acquires a lock using synchronize to safely operate on the @events array. It then finds the event with the shortest wait time, and sleeps the mutex for that period. That way other events can be added to the @events array using the appropriate lock, even while waiting. This supports the scheduler interface:
require "rack-timeout"
Scheduler = Rack::Timeout::Scheduler
Scheduler.run_in(5) { puts "I did a thing last!" }
Scheduler.run_in(3) { puts "whoop whoop, i'm second" }
Scheduler.run_in(1) { puts "yowza, i'm first" }
# yowza, i'm first
# whoop whoop, i'm second
# I did a thing last!
When you call run_in, a new event is appended to the @events array. run is called on the thread with the sleeping mutex , which causes @mx_events.sleep to wakeup and run_loop! to iterate again, checking for any events to fire and scheduling the shortest even duration to wait again using @mx_events.sleep.
def schedule(event)
@mx_events.synchronize { @events << event }
runner.run # wakes up the runner thread so it can recalculate sleep length taking this new event into consideration
return event
end
Similar to the principle of a database lock, the shorter you can keep the mutex lock the better for performance.
ConditionVariable
Similar to Mutex#sleep, a ConditionVariables purpose is to let you release a lock and sleep - you do that using the wait method. The difference is that it provides a direct communication mechanism to wake up: signal and broadcast. Let’s look at a small example - in it we won’t see the wait re-acquire the lock until we call signal:
mutex = Mutex.new
condition = ConditionVariable.new
t = Thread.new do
mutex.synchronize do
puts "hi!"
condition.wait(mutex)
puts "bye!"
end
end
t.join(5)
puts "how are you?"
t.join(1)
puts "still waiting?"
condition.signal
t.join
# hi!
# how are you?
# still waiting?
# bye!
signal will only notify a single thread, whereas broadcast will notify all threads. Let’s create two threads and try it signal instead:
def waiter(mutex, condition)
Thread.new do
mutex.synchronize do
puts "hi!"
condition.wait(mutex)
puts "bye!"
end
end
end
mutex = Mutex.new
condition = ConditionVariable.new
t = waiter(mutex, condition)
t2 = waiter(mutex, condition)
t.join(5)
puts "how are you?"
t2.join(1)
puts "still waiting?"
condition.signal
sleep 1
# hi!
# hi!
# how are you?
# still waiting?
# bye!
We never see the second thread say “bye!”, because only a single signal call has been made. A signal call attempts to wake up a single thread. If you try to join the second thread, Ruby will detect a deadlock condition because the wait will never finish:
condition.signal
t.join
t2.join
# hi!
# hi!
# how are you?
# still waiting?
# bye!
# main.rb:in `join': No live threads left. Deadlock? (fatal)
# 2 threads, 2 sleeps current:0x0000000001df10f0 main thread:0x0000000001df10f0
# * #<Thread:0x00007f9373bba9c8 sleep_forever>
# rb_thread_t:0x0000000001df10f0 native:0x00007f938d474300 int:0
# * #<Thread:0x00007f9371c124b8 main.rb:112 sleep_forever>
# rb_thread_t:0x00000000026ac400 native:0x00007f9371ace6c0 int:0
# depended by: tb_thread_id:0x0000000001df10f0
There are probably cases where signal makes sense - only one thread can acquire the lock so it’s cheaper to wake up a single thread than to wake up every thread. But broadcast covers more scenarios, and fixes our two thread example:
condition.broadcast
t.join
t2.join
# hi!
# hi!
# how are you?
# still waiting?
# bye!
# bye!
A ConditionVariable can only wait on a locked mutex:
mutex = Mutex.new
condition = ConditionVariable.new
t = Thread.new do
condition.wait(mutex)
end
sleep 1
puts thread_status(t)
#<ThreadStatus status="failed w/ error: Attempt to lock a mutex which is unlocked", error=#<ThreadError:...>
And only for the thread that owns the mutex:
mutex = Mutex.new
condition = ConditionVariable.new
t = nil
mutex.synchronize do
t = Thread.new do
condition.wait(mutex)
end
sleep 1
end
puts thread_status(t)
#<ThreadStatus status="failed w/ error: Attempt to unlock a mutex which is locked by another thread/fiber", error=#<ThreadError:...>
We can use ConditionVariable#wait with a timeout in seconds, so we can also recreate the Mutex#sleep Scheduler code from rack-timeout (in a more basic form):
class Scheduler
Schedule = Data.define(:block, :time)
def initialize
@mutex = Mutex.new
@cond = ConditionVariable.new
@schedules = []
start
end
def start
Thread.new do
loop do
@mutex.synchronize do
schedule = @schedules.min_by { |s| s.time }
if schedule
now = Time.now
sleep_duration = schedule.time - now
if sleep_duration > 0
@cond.wait(@mutex, sleep_duration)
end
if Time.now >= schedule.time
schedule.block.call
@schedules.delete(schedule)
end
else
@cond.wait(@mutex)
end
end
end
end
end
def schedule(seconds, &block)
@mutex.synchronize do
target_time = Time.now + seconds
@schedules << Schedule.new(block:, time: target_time)
@cond.signal
end
end
end
s = Scheduler.new
puts Time.now
s.schedule(1) { puts "1! #{Time.now}" }
s.schedule(3) { puts "2! #{Time.now}" }
s.schedule(5) { puts "3! #{Time.now}" }
sleep
# 2024-08-26 21:58:23 +0000
# 1! 2024-08-26 21:58:24 +0000
# 3! 2024-08-26 21:58:26 +0000
# 5! 2024-08-26 21:58:28 +0000
In Your Ruby programs are always multi-threaded: part 2, we looked at an example of coordinating threads using a “CountdownLatch”.
class CountdownLatch
def initialize(count)
@count = count
@mutex = Mutex.new
@cond = ConditionVariable.new
end
def wait
@mutex.synchronize do
@cond.wait(@mutex) while @count > 0
end
end
def count
@mutex.synchronize { @count }
end
def count_down
@mutex.synchronize do
@count -= 1
if @count == 0
@cond.broadcast
end
@count
end
end
end
📝 Quick reminder that
concurrent-rubycomes with a countdown latch so there’s no need to use this one ☝🏼. It’s just educational. It is very similar to the concurrent-ruby version though!
We’ve seen how wait and broadcast work. But why do we need that while @count > 0 check? Shouldn’t it only get woken up when @count == 0 and @cond.broadcast is called? Unfortunately, Mutex#sleep and ConditionVariable#wait can wake up randomly due to something called Spurious wakeups3.
Thread runtimes can decide for internal reasons to wake up a condition at random, so you should be ready to handle it - in our case we continually check the expected condition @count > 0 and continue to wait until it is false. This makes sure if we wake up due to a spurious wakeup we’ll immediately wait for the condition again.
Monitor
A Monitor is essentially the same as a Mutex, but it is also “re-entrant”. What does it mean to be re-entrant? Let’s go back to an example from Your Ruby programs are multi-threaded: part 2:
require "monitor"
class Result
attr_accessor :value
end
class Fibonacci
@fib_monitor = Monitor.new
class << self
def result=(value)
@fib_monitor.synchronize { @result = value }
end
def result
@fib_monitor.synchronize { @result }
end
def calculate(n)
@fib_monitor.synchronize do
self.result = Result.new
result.value = fib(n)
end
end
def fib(n)
return n if n <= 1
fib(n - 1) + fib(n - 2)
end
end
end
In it, when we call #calculate, internally it calls #result and #result=. calculate first acquires the lock using synchronize, then it calls result= which also tries to acquire the lock. It is re-entering the same lock. Let’s change @fib_monitor to a Mutex and see what happens:
class Fibonacci
@fib_monitor = Mutex.new
end
Fibonacci.calculate(10)
# `synchronize': deadlock; recursive locking (ThreadError)
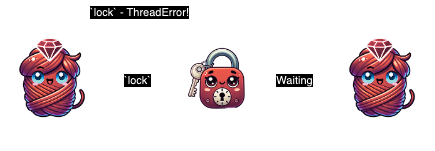
We immediately see an error raised: “deadlock; recursive locking”. By changing to a Monitor, everything works fine.
The redis-rb gem creates clients that are thread-safe. It uses a Monitor to do that, likely because it allows synchronized methods to call other synchronized methods without any recursive deadlocking errors:
class Redis
def initialize(options = {})
@monitor = Monitor.new
# ...
inherit_socket = @options.delete(:inherit_socket)
@client = initialize_client(@options)
@client.inherit_socket! if inherit_socket
end
def synchronize
@monitor.synchronize { yield(@client) }
end
def send_command(command, &block)
@monitor.synchronize do
@client.call_v(command, &block)
end
rescue ::RedisClient::Error => error
Client.translate_error!(error)
end
# lib/redis/commands/transactions.rb
def multi
synchronize do |client|
client.multi do |raw_transaction|
yield MultiConnection.new(raw_transaction)
end
end
end
Monitor comes with some other conveniences around creating ConditionVariables related to it, which you can read more about in its documentation.
Queue
Queue is one of two thread-safe data structures that come out of the box with Ruby. It is a First-in, First-out queue which allows for safe communication between threads. It’s primarily used for implementing producer/consumer patterns between threads:
queue = Queue.new
producer = Thread.new do
i = 0
loop do
queue << i
i += 1
sleep 1
end
end
def create_consumer(name, queue)
Thread.new do
loop do
item = queue.pop
puts "#{name} got another item #{item} at #{Time.now}"
end
end
end
create_consumer("Consumer 1", queue)
create_consumer("Consumer 2", queue)
producer.join
# Consumer 1 got another item 0 at 2024-08-24 20:58:46 +0000
# Consumer 2 got another item 1 at 2024-08-24 20:58:47 +0000
# Consumer 1 got another item 2 at 2024-08-24 20:58:48 +0000
# Consumer 2 got another item 3 at 2024-08-24 20:58:49 +0000
# Consumer 1 got another item 4 at 2024-08-24 20:58:50 +0000
# Consumer 2 got another item 5 at 2024-08-24 20:58:51 +0000
# Consumer 1 got another item 6 at 2024-08-24 20:58:52 +0000
# Consumer 2 got another item 7 at 2024-08-24 20:58:53 +0000
# Consumer 1 got another item 8 at 2024-08-24 20:58:54 +0000
# Consumer 2 got another item 9 at 2024-08-24 20:58:55 +0000
The producer thread endlessly adds an item to the queue every 1 second, and two consumer threads pop items off the queue. If there is no item available, the thread sleeps until one becomes available.
If it seems like you could pretty easily implement this using a Mutex and a ConditionVariable, you’d be right! I’ll leave that for you to try as an example.
SizedQueue
SizedQueue is the other thread-safe data structure available in Ruby, and it’s just another flavor of the base Queue class. It allows you to create a fixed-size queue - when new items are added the queue blocks until space is available.
fixed_queue = SizedQueue.new(3)
fixed_queue << 1
fixed_queue << 2
fixed_queue << 3
fixed_queue << 4 # raises "No live threads left. Deadlock?"
This is a good use-case for throttling your own code to not overwhelm your application. The following code will block if more than 5 items exist in the queue, throttling the producers so consumers can keep up with it:
throttle = SizedQueue.new(5)
# Producers
Thread.new do
i = 0
loop do
i += 1
if i.even?
throttle << "Producer 1: #{i}"
Thread.pass
end
end
end
Thread.new do
i = 0
loop do
i += 1
if i.odd?
throttle << "Producer 2: #{i}"
Thread.pass
end
end
end
# Consumers
Thread.new do
loop do
puts "Thread 1: #{throttle.pop}"
sleep 1
end
end
Thread.new do
loop do
puts "Thread 2: #{throttle.pop}"
sleep 2
end
end
loop do
puts "Threads waiting: #{throttle.num_waiting}"
sleep 0.5
end
# Threads waiting: 0
# Thread 1: Producer 1: 2
# Thread 2: Producer 2: 1
# Threads waiting: 2
# Thread 1: Producer 1: 4
# Threads waiting: 2
# Threads waiting: 1
# Thread 2: Producer 2: 3
# Thread 1: Producer 1: 6
# Threads waiting: 1
# Threads waiting: 2
# Thread 1: Producer 2: 5
# Threads waiting: 1
# Threads waiting: 2
# Thread 2: Producer 1: 8
# Thread 1: Producer 2: 7
You’ll see threads waiting going between 1 and 2, as producers get blocked while consumers slowly consume data from the SizedQueue.
ThreadGroup
The Ruby docs describe ThreadGroup as “a means of keeping track of a number of threads as a group.” A thread is automatically a part of the “default” group:
t = Thread.new { loop {} }
t.group == ThreadGroup::Default is # true
And you can add threads to a new group:
t = Thread.new { loop {} }
t2 = Thread.new { sleep }
group = ThreadGroup.new
group.add(t)
group.add(t2)
puts group.list
#<Thread:0x0...main.rb:1 run>
#<Thread:0x0...main.rb:2 sleep>
I’m mentioning them here for completeness, but you almost never see them in real use. See their documentation to learn more.
——
That’s about it! Out of the box, Ruby comes with a pretty small set of Thread primitives. Most code you might see in real use will use either these, or options from the concurrent-ruby gem. We’ll dig more into concurrent Ruby in “Abstracted, concurrent Ruby” later on in the series.
Memory visibility
The last thing we’ll discuss before finishing up is a concept called “memory visibility”.
The simplest way to think of memory visibility is “what can each thread can see at any given time”. When threads are running on multiple CPUs, a common optimization is to localize things to the most performant memory caches located on the CPU itself. If that happens, it means two different threads can operate on a shared piece of data, and have completely different views of that data because they have localized, out of sync versions of it.
In addition, the CPU can actually reorder certain operations to optimize them.
How can you solve these problems? When you need to make sure each thread sees a consistent, accurate version of a shared piece of data, you utilize something called a memory barrier. How can you use a memory barrier from Ruby? A mutex! As long as you wrap each access to a particular shared resource, you’ll be guaranteed to see a consistent view of it:
class AtomicBoolean
def initialize(default = false)
@value = default
@mutex = Mutex.new
end
def true?
@mutex.synchronize { value == true }
end
def false?
@mutex.synchronize { value == false }
end
def make_true
@mutex.synchronize { @value = true }
end
def make_false
@mutex.synchronize { @value = false }
end
end
Isolated to a single thread, or for immutable objects, memory visibility doesn’t really matter - it’s another reason attempting to share objects between threads can lead to issues, and avoiding it is better than trying to safely coordinate it.
📝 In CRuby, memory visibility is unlikely to ever be an issue for you. That’s because there is always a mutex involved when moving between threads: The GVL. We’ll talk more about the GVL in “Thread and its MaNy friends”. But to be on the cautious side, you’re better off synchronizing access consistently for reads/write to any data shared between threads.
———
We’ve now dug into the majority of the Thread API. The main piece we’ve only touched lightly, is around interrupting threads. It’s up next in “Interrupting Threads: Colorless, concurrent Ruby”. More soon! 👋🏼
-
There are a couple other interfacing for creating a thread, but you basically never see them in use.
a = 1
b = 2
Thread.new(a, b) { |a, b| puts a, b }
👆 this one has been described in some places as making copies to keep things thread safe - but that’s incorrect - it just passes the reference so it doesn’t provide much value ↩︎
-
You can handle signals in a couple ways that we’ll discuss later ↩︎
-
Spurious: not being what it purports to be; false or fake ↩︎