
👋🏼 This is a series on concurrency, parallelism and asynchronous programming in Ruby. It’s a deep dive, so it’s divided into 12 main parts:
- Your Ruby programs are always multi-threaded: Part 1
- Your Ruby programs are always multi-threaded: Part 2
- Ruby methods are colorless
- The Thread API
- Bitmasks, Ruby Threads and Interrupts, oh my!
- When good threads go bad
- Thread and its MaNy friends
- Fibers
- Processes, Ractors and alternative runtimes
- Scaling concurrency with streaming
- Abstracted, concurrent Ruby
- Closing thoughts, kicking the tires and tangents
- How I dive into CRuby concurrency
You’re reading “Your Ruby programs are always multi-threaded: Part 1”. I’ll update the links as each part is released, and include these links in each post.
- Part 1
- It’s all threaded
- Ok but how threaded is it really
- Threading mistakes
- Part 2
- Parting thoughts
- Tips for auditing gems 💎
- I use Falcon - Fibers are safe from this right?
- I use JRuby/TruffleRuby…
- Preforking / Reforking servers
- What about using mutexes for globals?
- It’s not doom and gloom, it’s detect and correct
- Takeaways 🥡
It's all threaded
If you run a web server using Puma, Falcon1, Webrick, or Agoo2, you use threads.
If you run background jobs using Sidekiq, GoodJob, SolidQueue3, or Que, you use threads.
If you use ActiveRecord, or Rails, you use threads.
If you use the NewRelic, DataDog, Sentry, LaunchDarkly, or Honeybadger gems, you use threads.
If you use net/http (or any gem internally using it like HTTParty or RestClient), httpx, or the Timeout4 gem, you use threads 🧵.
And because of the above, even if you use a forked, single-threaded server like Pitchfork or Unicorn, or run Puma in worker mode with no additional threads, or run jobs with Resque, or just use a basic Ruby rake task, you are using threads!
The point isn’t to be exhaustive. There are plenty more gems which use threads internally - you’re probably using some I haven’t listed. I’m also intentionally avoiding nuance - there are varying levels of threaded-ness.
The point is to demonstrate that threads are everywhere in Ruby, even if you are not working with them explicitly. Always write your code to be as thread safe as possible. Act as if you’re in highly threaded code and you’ll live a much happier life.
Ok but how threaded is it really
The degree of thread safety concern you need to have does vary depending on how threaded your Ruby environment is.
- Sidekiq, Puma, SolidQueue, or GoodJob: very threaded. If there are threading bugs in code you use they will come up, eventually.
- Falcon: Can be configured to be threaded. If it is, threading bugs will come up eventually. By default it only uses Fibers, which can still be susceptible to some concurrency issues.
- Pitchfork, Unicorn or Resque: not threaded, but you’re probably using threaded gems or writing threaded code. I’ll discuss later how these gems can still hit threading issues on process based servers, and other concurrency adjacent issues you might encounter.
- A one-off Ruby script with no gems - you exist in a thread but if it’s just something like processing files sequentially, practically not threaded. You’re probably fine, but YMMV 😬
It’s not just about writing explicitly threaded code that is safe to run. If you’re using Thread.new, you know you’re working with threaded code, and you know you need to proceed carefully. If you don’t know that, be careful! Threading has many sharp edges - it’s easy to get wrong.
Threads introduce non-determinism into your code - what works on one execution may not work on the next, even with identical inputs. It can lull you into a false sense of security, because that failure state may not appear for a long time. Writing safe threaded code takes careful analysis and planning.
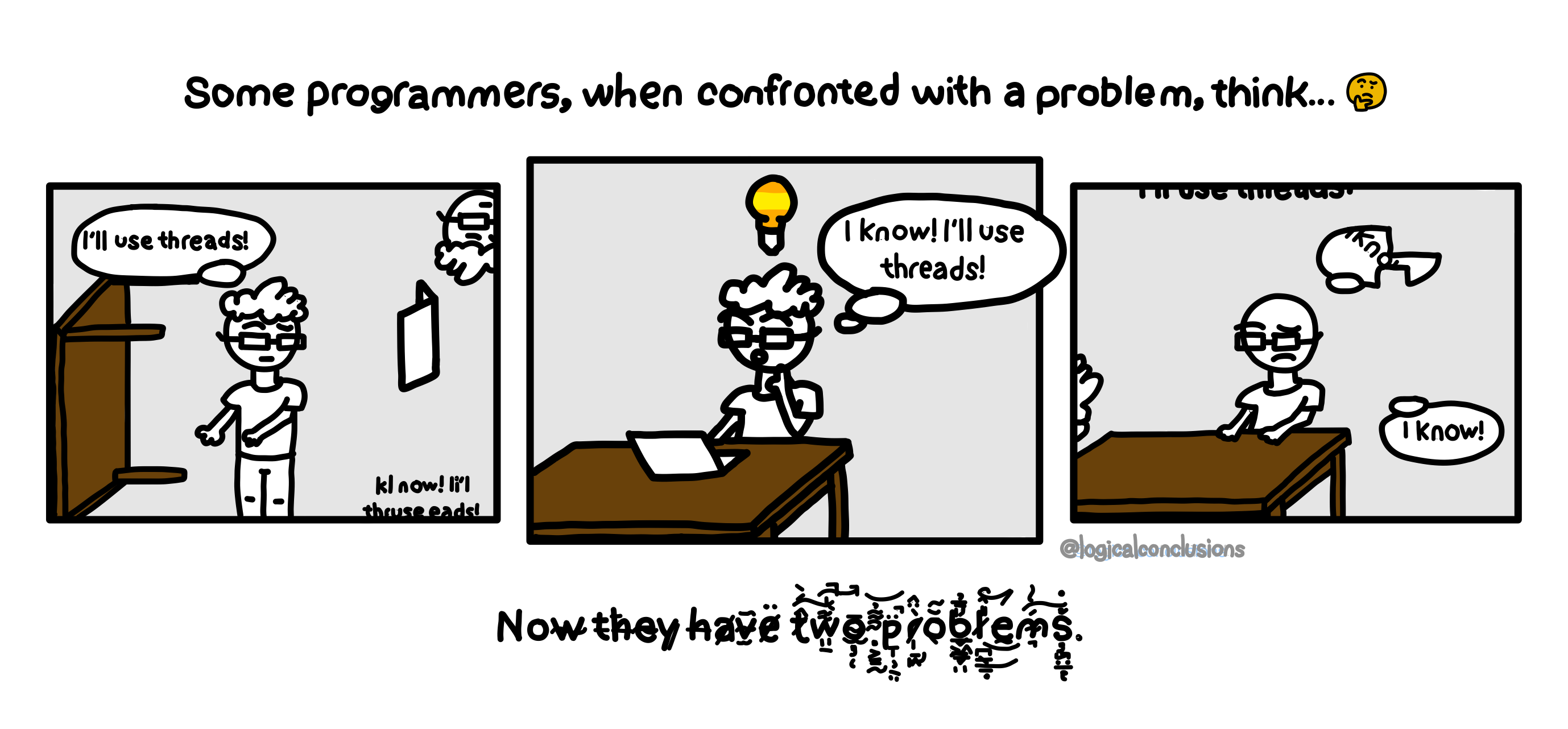
source: Eli and JP Camara, https://x.com/logicalcomic
Writing safe threaded code can be difficult, but writing safe non-threaded Ruby code in a threaded environment doesn’t have to be. There are some top mistakes I’ve seen (or personally made) to keep an eye out for in your own code, and code in gems you bring into your projects. Let’s take a look at them, and we’ll learn some core Ruby/CRuby principles along the way as well.
Threading mistakes
Sharing module/class instance variables
📝 For brevity, I’ll be referring to instance variables as “ivars”
If there’s a classic example of what not to do for thread safety, it’s maintaining and modifying class-level ivars5.
Not knowing that, you embark on implementing some file processing code. Finding yourself in need of code that splits a file into chunks by newline, you write the following:
class FileSplitter
def self.split(file_path, max_lines)
lines = []
files = []
File.open(file_path) do |file|
file.each_line do |line|
lines << line
if lines.size > max_lines
output = Tempfile.new
lines.each do |line|
output.write(line)
end
lines = []
files << output
end
end
# handle any remaining lines
if lines.size > 0
output = Tempfile.new
lines.each do |line|
output.write(line)
end
files << output
end
files
end
end
end
The split method takes a file path, a number of max lines per file, and returns an array of Tempfiles. Each Tempfile contains a chunk of the original file. In some cases you upload each chunk to a file service like S3, in other cases you hand them off to methods for further processing6.
The method is kind of hefty, and there’s some clear duplication so you decide to refactor.

source: https://theycantalk.com/post/710363232083361793/plans
You decide the logical split in the code is around writing to the temp files, a new method you’ll call write_lines. There are so many variables that it just seems easier to use ivars instead of passing everything around.
class FileSplitter
def self.split(file_path, max_lines)
@lines = []
@files = []
File.open(file_path) do |file|
file.each_line do |line|
@lines << line
write_lines(max_lines)
end
# force remaining to write
write_lines
@files
end
end
def self.write_lines(max = nil)
return if @lines.empty?
if max.nil? || @lines.size > max
@output = Tempfile.new
@lines.each do |line|
@output.write(line)
end
@lines = []
@files << @output
end
end
end
Since the method is at the class level, the ivars are class level as well. For any code calling these methods, they only exist once. Every thread shares the same class object.
📝 If this doesn’t look like class-level ivars, you may be used to the more explicit syntax using double at-signs. For example,@@lines. These are equivalent, but when you’re inside a class method, class-level ivars only need one at-sign. When inside a class method, the instance is the class itself.
Another format of this would be a class levelattr_accessor. So if you see a class method withself.lines = []or see code likeFileSplitter.lines = [], these can also be class level ivars!Some commenters have pointed at that the above is not accurate - until I update it more accurately, see the ruby lang docs for more information about class level instance variable differences
You are running this code in a background job using Sidekiq, running with multiple threads on CRuby 3.3. Most of the time the job runs fine, but you’ve received a few reports from people missing data, and some people even seeing data that wasn’t in their files! Uh oh, what is happening?!
The problem is that every thread is sharing the same data, and modifying it concurrently. If multiple jobs are running and calling FileSplitter.split, they are all trying to write to the same piece of memory. We can follow along with the code line by line to see where things break down:
### Thread 1
# FileSplitter.split(path, max) ->
@lines = []
@files = []
# ...
@output = Tempfile.new
@output.write(line) # `write` causes the thread to sleep so Thread 2 starts
### Thread 2
# Calling `split` resets the instance variables
# Now each thread is using the same variables!
# FileSplitter.split(path, max) ->
@lines = []
@files = []
# ...
# Next time it wakes up, Thread 1 will be appending to the same array as Thread 2 💀
@lines << line
# ...
# Thread 1's Tempfile is overwritten and lost, along with anything written to it 👋🏼
@output = Tempfile.new
@output.write(line) # Now `write` causes Thread 2 to sleep
### Thread 1 wakes up and continues processing
# The next line from Thread 1 gets written to the output file from Thread 2
# We are now 100% off the rails...
# Pour one out for our mix and matched
# user data ☠️☠️☠️
@lines.each do |line|
@output.write(line)
end
Or the same flow, visualized:
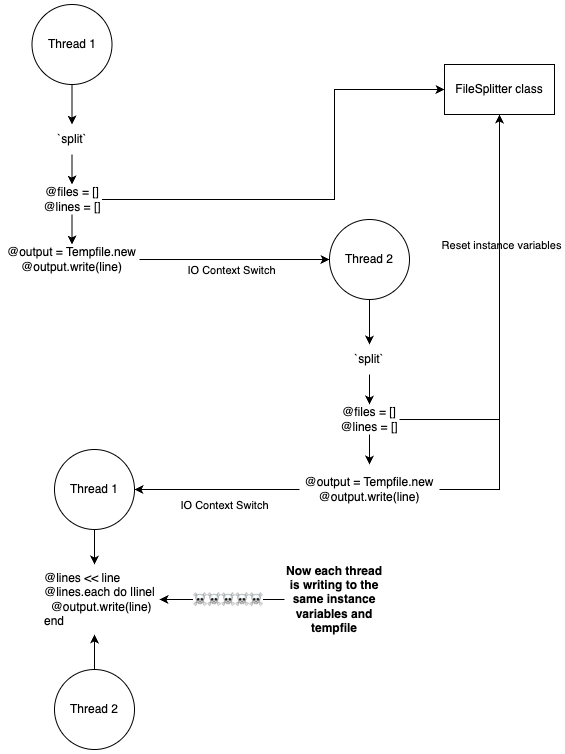
source: jpcamara.com
The simplest advice about the above code?
Don’t use shared instance variables in classes, ever 🙅🏻♂️. Assume that a class level ivar is a code smell, until proven otherwise.
📝 There is a caveat to this, and its configuration and initialization class level ivars. It is common to set global configuration values and macros7 using class level ivars. The difference is that these are written once on load of your application, and then only ever read past that point. If they are not properly frozen you could still corrupt them by modifying them during program execution. Which is why things like Rails middleware
freezethe middleware array to try and avoid this issue.
How can we make this code thread safe? Use regular Ruby instances. We don’t have to change much.
class FileSplitter
def initialize(file_path, max_lines)
@file_path = file_path
@max_lines = max_lines
@lines = []
end
def split
@files = []
File.open(@file_path) do |file|
file.each_line do |line|
@lines << line
write_lines(max_lines)
end
# force remaining to write
write_lines
@files
end
end
private
def write_lines(max = nil)
return if @lines.empty?
if max.nil? || @lines.size > max
# Also remove @output as an ivar,
# we only use it right here so it
# being an ivar wasn't necessary
output = Tempfile.new
@lines.each do |line|
output.write(line)
end
@lines = []
@files << output
end
end
end
Now when you use this code, each thread creates its own FileSplitter:
### Thread 1
splitter = FileSplitter.new(path, max)
splitter.split
### Thread 2
splitter = FileSplitter.new(path, max)
splitter.split
Each thread now safely uses its own independent, isolated instance 😌.
Heisenbugs

A heisenbug is a software bug that seems to disappear or alter its behavior when one attempts to study it.
The term is a pun on the name of Werner Heisenberg, the physicist who first asserted the observer effect of quantum mechanics, which states that the act of observing a system inevitably alters its state.
The effects of sharing class-level ivars can be deceptive. For instance, try running the following:
class Result
attr_accessor :value
end
class Fibonacci
class << self
attr_accessor :result
def calculate(n)
self.result = Result.new
self.result.value = fib(n)
end
def fib(n)
return n if n <= 1
fib(n - 1) + fib(n - 2)
end
end
end
answers = [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144]
answers.size.times.map do |n|
Thread.new do
Fibonacci.calculate(n)
answer = answers[n]
result = Fibonacci.result.value
if result != answer
raise "[#{result}] != [#{answer}]"
end
end
end.map(&:join)
Here we have a naive8, basic Fibonacci generator, and we verify each result against an array of precomputed results. We spawn as many threads as there are precomputed results to calculate against. We’re storing the result in a class-level ivar that is being shared across threads - that shouldn’t end well! If any results don’t match, we raise an error.
Run this example and… it doesn’t fail in CRuby 🤔. This might lull you into thinking it isn’t an issue.
Is CRuby somehow thread safe? No, we’ve already established with the FileSplitter example that it is not inherently thread safe.
Maybe that Global VM Lock (GVL) you’ve heard about is protecting you from this issue? Unintentionally, yes.
In CRuby, only one thread running Ruby code can run at a time. That means for our example you can’t get our class data to overwrite without what’s called a “context switch”: something that would cause the Ruby runtime to swap between our threads, even mid operation like in a method call or variable assignment.
There are two common reasons context gets switched between threads in CRuby, which can result in operations only partially completing (ie, setting the proper result, then checking that result):
- ~100ms of Ruby processing have elapsed
- A blocking operation has been invoked
Neither of these cases are met by our example. You’re benefiting from low overhead and a lack of blocking operations - there isn’t enough going on to cause a context switch. Without (1) or (2), each thread runs and completes in entirety before the next thread runs.
📝 If you don’t know what the GVL is - or only know it from a high level - you’ll learn all about it in “Concurrent, colorless Ruby” later on
I titled this section “Heisenbugs” because you can get the bug to happen by altering things in what would appear to be innocuous ways. We’ll try two things:
For (1), we’ll try with more calculations:
answers = [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, 196418, 317811, 514229, 832040, 1346269, 2178309, 3524578, 5702887, 9227465, 14930352, 24157817]
answers.size.times.map do |n|
Thread.new do
Fibonacci.calculate(n)
answer = answers[n]
result = Fibonacci.result.value
if result != answer
raise "[#{result}] != [#{answer}]"
end
end
end.map(&:join)
💥! We get an error raised! So what happened?
[] != [832040] (RuntimeError)
In the recursive Fibonacci solution, the code gets exponentially slower the more numbers we try to generate. And we now know when pure Ruby code is being run, the CRuby thread scheduler only allows each thread to run in 100ms time slices. This is so each thread can share processing time.
📝 CPU intensive work doesn’t run more efficiently with threads in CRuby, but you will still encounter it on threaded servers.
We can see this time slicing in action with the gvl-tracing gem, which creates a timeline of thread context switching using the CRuby GVL Instrumentation API:
require "gvl-tracing"
GvlTracing.start("timeline.json") do
answers.size.times.map do |n|
Thread.new do
Fibonacci.calculate(n)
answer = answers[n]
result = Fibonacci.result.value
if result != answer
raise "[#{result}] != [#{answer}]"
end
end
end.map(&:join)
end

source: jpcamara.com
Our threads’ running slices form a sort of waterfall because of the GVL. They spend most of their time in the wants_gvl state, which means they’re ready for work but are waiting to acquire the GVL. When they run, they can only hold the GVL for around 100ms of Ruby processing before the CRuby scheduler passes control to another thread. You see each thread in a running state for small slices of time - the highlighted thread ran 97ms before having control pass back. As the Fibonacci numbers get larger, the threads need more 100ms slices to finish, which is why each thread has so many running blocks.
It’s also why we start to hit issues with our class level ivars. The scheduler can stop a thread mid operation, or in between variable assignments. It takes more iterations than shown, but we can visualize the issue like this:
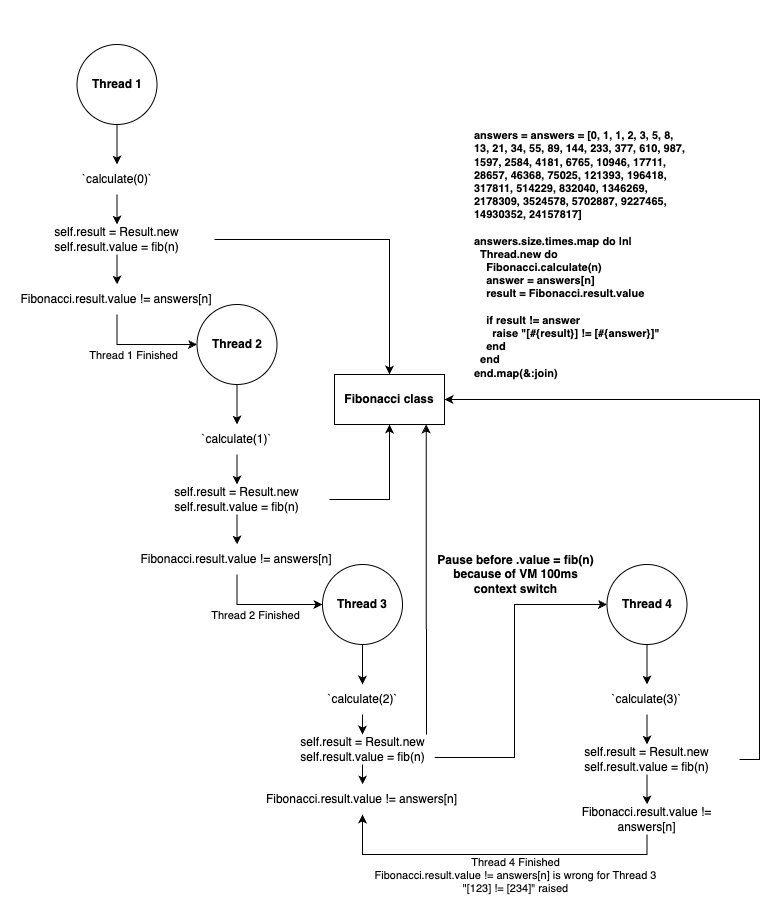
source: jpcamara.com
Can we try a bit harder and get our original example to break as well? Even though it has low throughput?
Let’s create a helper to simulate some load.
require "concurrent-ruby"
def run_forever(pool_size: 10)
pool = Concurrent::FixedThreadPool.new(
pool_size
)
i = Concurrent::AtomicFixnum.new
loop do
pool.post do
yield i.increment
end
end
end
In the run_forever method we utilize a gem called concurrent-ruby to endlessly run our code across multiple threads. It uses a pool of 10 threads, and each time a thread runs it maintains a thread-safe counter which it yields as the current iteration. We can now use it to run our original Fibonacci example:
answers = [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144]
run_forever do |iteration|
n = iteration % answers.size
Fibonacci.calculate(n)
answer = answers[n]
result = Fibonacci.result.value
if result != answer
raise "[#{result}] != [#{answer}]"
end
rescue => e
puts "Iteration[#{iteration}] #{e.message}"
end
💥. This time, we start seeing errors!
Iteration[36981] [13] != [34]
Iteration[154569] [89] != [144]
Iteration[173571] [89] != [21]
Iteration[197573] [] != [144]
Iteration[199483] [] != [89]
Iteration[201395] [] != [144]
Iteration[203330] [] != [55]
Iteration[207180] [5] != [144]
Iteration[209117] [5] != [144]
Iteration[211039] [5] != [55]
Iteration[214849] [5] != [89]
Iteration[234986] [8] != [89]
Iteration[221961] [1] != [144]
Iteration[223872] [1] != [144]
Iteration[225767] [1] != [34]
Iteration[244243] [0] != [144]
Iteration[218269] [1] != [144]
Iteration[236807] [8] != [144]
Iteration[240446] [55] != [89]
Iteration[231318] [1] != [34]
Iteration[246175] [0] != [13]
For (2), let’s try it again but call puts, a blocking operation:
answers.size.times.map do |n|
Thread.new do
Fibonacci.calculate(n)
puts "Get ready to check for #{n}!"
answer = answers[n]
result = Fibonacci.result.value
if result != answer
raise "[#{result}] != [#{answer}]"
end
end
end.map(&:join)
puts gives us a pretty reliable failure:
[144] != [0] (RuntimeError)
Get ready to check for 1!
The same basic idea happens - we perform the calculation, but before checking the result we print the message Get ready to check for #{n}!. This is a blocking operation in CRuby9 - it causes our thread to yield and another thread to get scheduled. When the original thread regains control there’s a good chance the value has been swapped out and the comparison will fail. This is the main reason our original FileSplitter code failed so reliably - the Tempfile write method is a blocking operation and caused a context switch.
Ruby internals
Interesting side note, this was my original code for this section, which I initially tried on CRuby 3.2.
class Repeater
class << self
attr_accessor :result
def repeat_by(content, n)
self.result = [content] * n
end
end
end
100.times do
100.times.map do |n|
Thread.new do
Repeater.repeat_by("hello", n)
array_size = Repeater.result.size
if array_size != n
raise "[#{array_size}] should be [#{n}]?"
end
end
end.map(&:join)
end
[88] should be [98]? (RuntimeError)
That code failed reliably on Mac and Linux on Ruby 3.2. But on Ruby 3.3, I couldn’t get it to fail no matter how many times I ran it. Even between minor Ruby versions the thread internals can change enough to invalidate an evaluation of unsafe code. In this case the code benefited from the change, but there are no guarantees the next version won’t fail even more frequently than 3.210.
Using our run_forever helper, however, we can eventually get this to fail on CRuby 3.3:
run_forever do |iteration|
n = rand(100)
Repeater.repeat_by("hello", n)
array_size = Repeater.result.size
if array_size != n
raise "[#{array_size}] should be [#{n}]?"
end
rescue StandardError => e
puts "Iteration[#{iteration}] #{e.message}"
end
Iteration[323650] [52] should be [35]?
Iteration[408269] [59] should be [18]?
Iteration[563087] [51] should be [16]?
Iteration[623992] [8] should be [91]?
It takes hundreds of thousands of attempts but it does ultimately fail. But why did running it so many times cause it to fail? There’s no blocking operation. It shouldn’t take 100ms to run. In “Concurrent, colorless Ruby” we’ll dig even further into other reasons your thread context switches.
Back in reality...
The community has a much better understanding of this type of issue now vs 10+ years ago. But it still happens and I’ve seen it recently in gems, even ones that are well maintained.
Watch out for this in your own code. Watch out for this in code reviews. Watch out for this in gems. If you see it and it seems to run ok, use run_forever and you’ll likely see it fail.
Assume shared class instance variables are a bad idea. Knowing that you try something new…
Copying state to instances
You’re maintaining the please_encrypt gem (a very polite encryption layer), and you have a class level macro that defines which attributes to encrypt:
class Member
include PleaseEncrypt
please_encrypt :home_address, :phone
end
Learning from your FileSplitter issue, you’ve removed all of your shared class level ivars in the gem. But you’ve just added a new class level ivar that you’re sure is safe.
You know not to share class-level instance variables, but you are now using some for default values. The macro defines class level ivars containing metadata about the encryption. It’s only defined once on class load, so you won’t be contending with threads overwriting each other11.
When an instance uses the encryptables metadata, you dup the original value so nothing gets shared by accident:
# member.rb
class Member
include PleaseEncrypt
please_encrypt :home_address, :phone
end
# please_encrypt.rb
module PleaseEncrypt
# ...
def pleasant_options
# `dup` to avoid sharing across threads
@pleasant_options ||= self.class.encryptables.dup
end
def pleasant_attributes
@pleasant_attributes ||= # ...
end
module ClassMethods
attr_accessor :encryptables
def please_encrypt(*fields)
self.encryptables = {}
fields.each do |field|
self.encryptables[field] = {
algorithm: "AES-256-GCM",
key_method: :generate_key
}
define_method("#{field}=") do |value|
result = encrypt(field, value)
pleasant_attributes[field][:encrypted] = result
end
define_method(field) do
decrypt(
field,
pleasant_attributes[field][:encrypted]
)
end
end
end
end
def encrypt(field, value)
options = pleasant_options[field]
cipher = OpenSSL::Cipher.new(
options[:algorithm]
)
options[:key] = send(options[:key_method])
cipher.encrypt
# ...
end
def decrypt(field, value)
options = pleasant_options[field]
# ...
end
# ...
end
We’ll look at the full code later, but this highlights the major points. When please_encrypt is called it takes each symbol and makes them into readers and writers. When setting the field the value is encrypted. When getting the field the value is decrypted. Pleasant!
You release a new version of your gem and a few weeks after release you start seeing issues open up!
😥
😰
😱
You haven’t seen anything like this in your testing and can’t manage to reproduce it. What is going on?
A user has reported the only way they can reliably reproduce it. It requires running code using please_encrypt inside of sidekiq jobs for 3-5 minutes straight.
class EncryptionFailureJob
include Sidekiq::Job
def perform
m = Member.new
m.phone = "123-456-7890"
m.phone
end
end
# sidekiq -C 10
loop do
EncryptionFailureJob.perform_async
end
The user can “fix” the error by forcing a retry in the code:
def perform
m = Member.new
m.phone = "123-456-7890"
m.phone
rescue OpenSSL::Cipher::CipherError
puts "retrying..."
retry
end
You can use this code to reproduce the issue, and it always succeeds within one retry 👀.
Running this way, after a few minutes you usually see an OpenSSL::Cipher::CipherError. Yay…
But why does it take so long? Maybe the overhead of Sidekiq interacting with Redis and managing the job server is reducing load. You know how you can get some load - run_forever!
run_forever do |iteration|
m = Member.new
m.phone = "123-456-7890"
m.phone
rescue => e
puts "Iteration[#{iteration}] #{e.class}"
end
Doing that, you’re able to raise an OpenSSL::Cipher::CipherError pretty quickly:
Iteration[3591] OpenSSL::Cipher::CipherError
Iteration[8093] OpenSSL::Cipher::CipherError
Iteration[12229] OpenSSL::Cipher::CipherError
Iteration[13368] OpenSSL::Cipher::CipherError
Iteration[18023] OpenSSL::Cipher::CipherError
Iteration[38276] OpenSSL::Cipher::CipherError
Iteration[63144] OpenSSL::Cipher::CipherError
You look through recent changes. Luckily, in your case the most recent change you made was your attribute dup, so you look deeper into that code. Is something wrong with the ||= maybe?
Here’s the full source code. Can you find the issue?
⚠️ This is working code so you can try it to replicate the issue. It will properly encrypt and decrypt. But it is not meant for real use! Use real, vetted libraries for anything encryption/security related 🔐
module PleaseEncrypt
def self.included(base)
base.extend ClassMethods
end
module ClassMethods
attr_accessor :encryptables
def please_encrypt(*fields)
self.encryptables = {}
fields.each do |field|
self.encryptables[field] = {
algorithm: "AES-256-GCM",
key_method: :generate_key
}
define_method("#{field}=") do |value|
result = encrypt(field, value)
pleasant_attributes[field][:encrypted] = result
end
define_method(field) do
decrypt(
field,
pleasant_attributes[field][:encrypted]
)
end
end
end
end
def encrypt(field, value)
options = pleasant_options[field]
cipher = OpenSSL::Cipher.new(
options[:algorithm]
)
options[:key] = send(options[:key_method])
cipher.encrypt
options[:iv] = cipher.random_iv
cipher.key = options[:key]
encrypted = cipher.update(value) + cipher.final
options[:auth_tag] = cipher.auth_tag
Base64.encode64(encrypted)
end
def decrypt(field, value)
options = pleasant_options[field]
cipher = OpenSSL::Cipher.new(
options[:algorithm]
)
data = Base64.decode64(value)
cipher.decrypt
cipher.iv = options[:iv]
cipher.auth_tag = options[:auth_tag]
cipher.key = options[:key]
cipher.update(data) + cipher.final
end
def pleasant_options
@pleasant_options ||= self.class.encryptables.dup
end
def pleasant_attributes
@pleasant_attributes ||= hash_defaulter
end
def as_json
pleasant_attributes.inject(hash_defaulter) do |hash, (k, v)|
hash[k][:encrypted] = v[:encrypted]
hash[k][:iv] = pleasant_options[k][:iv]
hash[k][:auth_tag] = pleasant_options[k][:auth_tag]
hash
end
end
private
def generate_key
OpenSSL::Random.random_bytes(32)
end
def hash_defaulter
Hash.new do |h, k|
h[k] = {}
end
end
end
class Member
include PleaseEncrypt
please_encrypt :home_address, :phone
end
You print the options and attributes, which is when you see the following:
m = Member.new
m.phone = "123\n456\nok!"
m.home_address = "..."
puts m.pleasant_attributes
puts m.pleasant_options
{
home_address: { ... },
phone: { ... }
}
Oh no… you’re dup’ing the class-level data (good!), but because dup only performs a shallow copy, you are sharing nested objects (bad!).
members = [
Member.new,
Member.new,
Member.new
]
puts 'options id'.ljust(12) +
' | home_address id'.ljust(18) +
' | phone id'.ljust(12)
puts '-----------------------------------------'
members.each do |member|
opts = member.pleasant_options
puts opts.object_id.to_s.ljust(15) +
opts[:home_address].object_id.to_s.ljust(18) +
opts[:phone].object_id.to_s.ljust(12)
end
This means that per class, per attribute, every thread is modifying the same hash 😩, even across what seemed like independent instances. When we print the object_id on each of the hashes, we see that the top-level hash is unique, but the nested hashes are all the same object.
options id | home_address id | phone id
-----------------------------------------
2000 1920 1960
2020 1920 1960
2040 1920 1960
But why does it take high load to break? You have your suspicions…

Threading issues in CRuby can be ticking time-bombs. The GVL blocks parallel execution of Ruby code, so it takes more effort to force the right timing for unsafe context switches. If you see code that seems like it’s not thread safe but “works” - assume it will eventually break.
The fix is frustratingly simple:
def pleasant_options
@pleasant_options ||= begin
duplicate = {}
self.class.encryptables.each do |k, v|
duplicate[k] = v.dup
end
duplicate
end
end
Now you are duplicating the nested hashes as well. With this change, you no longer share any data between the class and the instances. Rerunning the run_forever example there are no more errors 🙌🏼.
This does leave you susceptible to deeply nested hashes being shared. If you’re using ActiveSupport or Rails, I’d recommend using deep_dup, which handles nested hashes. If not, you could write a recursive method to handle it, or check for a gem (there seem to be many).
Back in reality... part two
If this whole scenario seemed oddly specific, it’s because it is based on a real gem issue. This exact problem remained an open issue for years in the attr_encrypted12 gem without anyone identifying the issue. All of the GitHub issue images are from real issues - running in Sidekiq and usually under load they saw intermittent encryption errors.
How could this have been avoided? The simplest answer will sound familiar: don’t share class-level state. Even though in this case the sharing was unintentional, the macro metadata could have instead been used separate rather than trying to mix it into the instance:
def encrypt(field, value)
options = pleasant_options[field]
cipher = OpenSSL::Cipher.new(
options[:algorithm]
)
options[:key] = send(self.class.encryptables[field][:key_method])
# ...
end
def decrypt(field, value)
options = pleasant_options[field]
cipher = OpenSSL::Cipher.new(
self.class.encryptables[field][:algorithm]
)
# ...
end
def pleasant_options
@pleasant_options ||= {}
end
This is easy to see in hindsight but is very easy to overlook in a larger code base.
attr_encrypted is not Rails specific, technically. But if you’re in the Rails world using ActiveRecord you should use the built-in encryption instead.
Cleaning up thread state
😮💨
Now you’re thinking “is there a way I can avoid all of these headaches?”. You’re so tired of these class level ivars and their surprising behaviors. You’ve heard about something called “thread-locals” that sound really promising. They stay silo’d to your thread and can even act “global”13 without any chance of sharing14 😍.
As a test, you use them on the Fibonacci example from earlier and can’t reproduce any issues 😌. Within the thread its global, but each thread has its own local state, isolated from the others.
class Fibonacci
class << self
def result
Thread.current[:fib_result]
end
def result=(value)
Thread.current[:fib_result] = value
end
def calculate(n)
self.result = Result.new
self.result.value = fib(n)
end
def fib(n)
return n if n <= 1
fib(n - 1) + fib(n - 2)
end
end
end
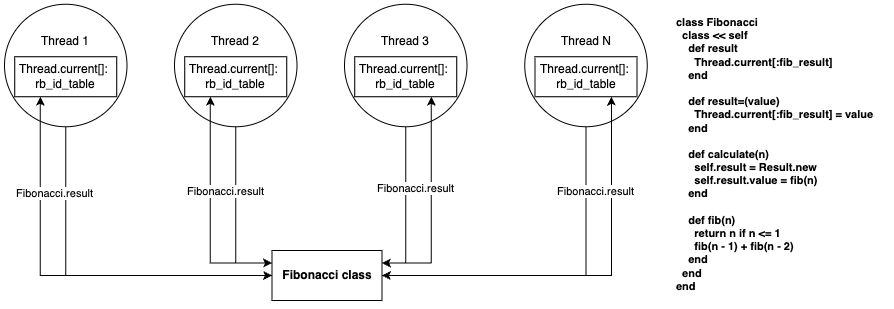
source: jpcamara.com
No class level ivars ✅ , no duping ✅. Feeling confident that it’s a good approach when you need something global, you put this solution in your mental back pocket.
Now you’re writing a new application - It’s a Rails app for sharing articles (because we don’t have enough of those), with a User and Article model:
class User < ApplicationRecord
has_many :articles
end
class Article < ApplicationRecord
end
It’s a typical CRUD web application, and a couple requirements come up:
- Track the origin of a change. If an article is added, updated or deleted, a record is created to keep track of who did it and when.
- Add some I18N. You’ve got Japanese and Polish users going wild for this highly original site.
There’s so many places you could need to access this information, you decide to store it in a thread-safe, global way using thread-locals 🙌🏼.
class AppContext
class << self
def user
Thread.current[:app_user]
end
def user=(user)
Thread.current[:app_user] = user
self.locale = user.locale
end
def locale
Thread.current[:app_locale]
end
def locale=(locale)
Thread.current[:app_locale] = locale
end
end
end
📝 Not to spoil the ending, but ultimately I will recommend you avoid directly using
Thread.current[]in favor of other solutions, particularly since we’ll find later that it being “thread-local” is not really accurate.Just in case you get so excited at the idea of
Thread.current[]you start feverishly writing code using it and never finish reading part 2 🏃♂️
You use the thread-local data to pass the user into the Change we save.
# app/controllers/application_controller.rb
class ApplicationController
def set_user
AppContext.user = User.find(cookies.encrypted["user_id"])
end
end
# app/models/articles_controller.rb
class ArticlesController < ApplicationController
before_action :set_user
def create
Article.create!(article_params)
end
end
# app/models/change.rb
class Change < ApplicationRecord
belongs_to :trackable, polymorphic: true
belongs_to :user
end
# app/models/article.rb
class Article
include Trackable
end
# app/models/concerns/trackable.rb
module Trackable
extend ActiveSupport::Concern
included do
before_save :track_changes
before_destroy :track_destroy
has_many :changes, as: :trackable
end
private
def track_changes
action = if new_record?
"create"
else
"update"
end
track_change(action)
end
def track_destroy
track_change("delete")
end
def track_change(action)
Change.create(
trackable: self,
action:,
changes: attributes,
user: AppContext.user
)
end
end
This seems to work really well. Well enough that you decide to expose a change history to your users so they can see edits that have been made to an article, and by who.
class ArticlesController < ApplicationController
# ...
def show
@article = Article.find(params[:id])
end
end
<!-- app/views/articles/show.html.erb -->
<h1><%= t('articles.changes.title') %></h1>
<table>
<thead>
<tr>
<th><%= t('articles.changes.headers.article_id') %></th>
<th><%= t('articles.changes.headers.action') %></th>
<th><%= t('articles.changes.headers.changes') %></th>
<th><%= t('articles.changes.headers.user') %></th>
<th><%= t('articles.changes.headers.changed_at') %></th>
</tr>
</thead>
<tbody>
<% @article.changes.each do |change| %>
<tr>
<td><%= change.trackable_id %></td>
<td><%= t("articles.changes.actions.#{change.action}") %></td>
<td>
<ul>
<% change.changes.each do |attribute, value| %>
<li><%= t("articles.attributes.#{attribute}") %>: <%= value %></li>
<% end %>
</ul>
</td>
<td><%= change.user.email %></td>
<td><%= l(change.created_at, format: :long) %></td>
</tr>
<% end %>
</tbody>
</table>
Things are going smoothly, but what good is posting articles without being able to discuss them?
# app/models/article.rb
class Discussion
include Trackable
end
# app/controllers/discussions_controller.rb
class DiscussionsController < ApplicationController
def create
Discussion.create!(discussion_params)
end
def show
@discussion = Discussion.find(params[:id])
end
end
# assume a near identical "changes" view...
You test this out and it works on your machine 😬. Guess it’s time to deploy 🤷🏻♂️.
Except… once you deploy these changes, you start receiving some weird reports from users. Users will sometimes see discussions render in a totally random language. Even worse, some changes are showing up associated with unrecognized users!
Co się dzieje?!
何が起こっているの?!
What is happening?!
You analyze your database and logs, and notice something strange:
- The changes are only ever wrong for the
Discussionmodel - The internationalizations are only ever wrong in the discussions views
What’s the difference between ArticlesController and DiscussionsController?
class ArticlesController < ApplicationController
before_action :set_user
def create
Article.create!(article_params)
end
end
class DiscussionsController < ApplicationController
def create
Discussion.create!(discussion_params)
end
end
Oh simple, there it is, you’re not setting AppContext.user in the discussions controller. But if it’s not getting set then why is it a different user and locale? Why is it set to anything at all?
You check the docs for thread-locals only to find…
- They exist for the lifetime of the thread
- You know that everything in Ruby runs in a thread
- On multi threaded servers like Puma, threads are reused between requests so they can leak data you don’t clear out
- Even on single threaded servers like Unicorn, you still run within the Ruby “main” thread (
Thread.main). So you can even leak data you don’t clear out in single-threaded servers 🫠
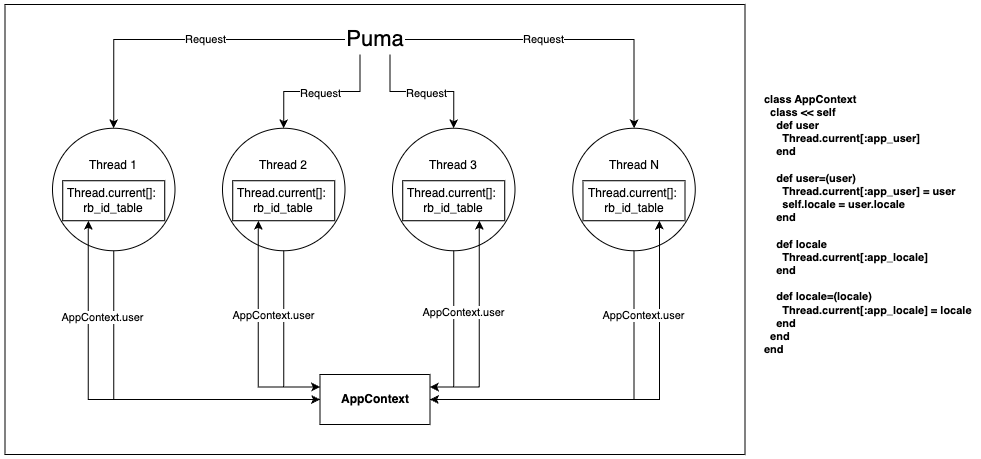
source: jpcamara.com
Well that was pretty bad. Whenever a user went to the DiscussionsController, it would use information from whichever user used that thread last. It might be the same user, but it could just as easily be someone else.
You make sure they get set on every controller now, but also get cleared out in every controller too.
class AppContext
# ...
def clear
[:app_user, :app_locale].each do |key|
Thread.current[key] = nil
end
end
end
class ApplicationController
after_action :clear_app_context
def clear_app_context
AppContext.clear
end
end
class DiscussionsController < ApplicationController
before_action :set_user
# ...
end
Now if someone forgets to add it to their controller, it won’t be set to any user at all - at the end of every request the thread-local is cleared out so it won’t be present15.
You deploy the change and almost everything is good.
- Locales are good! No more Polish for English users, or Japanese for Polish users.
- When someone posts to a discussion, it consistently shows the right user in the change history 😮💨
- But, there’s still an intermittent change showing up as the wrong user. What other code is there?
The controllers are good. How are the background jobs?
class FirstTimePostingJob < ApplicationJob
def perform(user)
AppContext.user = user
Congrats.new(user).call
end
end
class ImageUploadJob < ApplicationJob
def perform(article, file_url)
# Uploads to a service
article.upload_from_url(file_url)
end
end
You’re setting the user in one job, and picking it up in another 🤦🏻♂️. When the article is updated to add an image using the file_url, sometimes the change is null, and sometimes it’s a totally random user. Hardly ever is it the actual user that added the image 😩.
The same thing you did with controllers, you can’t forget to do in jobs. You need to clean them up the same way (after an action/job finishes), but the logic goes in a new place.
If you're using Sidekiq
If you’re using a mixture of Sidekiq and ActiveJob, or Sidekiq alone, a Sidekiq Middleware is your best option. It will work for both job types because it is called internally by the Sidekiq server when performing a job.
class ContextClearMiddleware
include Sidekiq::ServerMiddleware
def call(_worker, _job, _queue)
yield
ensure
AppContext.clear
end
end
Sidekiq.configure_server do |config|
config.server_middleware do |chain|
chain.add ContextClearMiddleware
end
end
If you're using ActiveJob
If you exclusively use ActiveJob, then an after_perform in your base job class should work just as well, and will work even if you’re using SolidQueue, GoodJob, or any other job adapter that hooks into ActiveJob.
class ApplicationJob < ActiveJob::Base
after_perform :clear_app_context
def clear_app_context
AppContext.clear
end
end
Next Up
source: jpcamara.com
This is the first step into this Ruby concurrency series. In Part 2 we’ll dig into a few more topics: true thread locals + fibers, the layered Ruby concurrency model, reusing objects, some more complex threading coordination, and ideas for keeping your code and your dependencies thread safe. More soon 👋🏼!
-
It doesn’t have to use threads by default, but there’s a good chance you are configured for some ↩︎
-
None of these servers force you to use multiple threads, but will usually use them by default. Puma’s OOTB configuration in rails uses 3 threads, for instance. https://github.com/rails/rails/blob/main/railties/lib/rails/generators/rails/app/templates/config/puma.rb.tt
They use some threads internally as well even if you don’t serve requests using more than 1 thread, possibly with the exclusion of Falcon since its core is the FiberScheduler. ↩︎
-
You also don’t have to use these job queues with threads either. But they all use them by default, or at least have internal threaded elements. ↩︎
-
You shouldn’t though.
http://blog.headius.com/2008/02/ruby-threadraise-threadkill-timeoutrb.html
https://www.mikeperham.com/2015/05/08/timeout-rubys-most-dangerous-api/
But if you’re using net-http, you’re using the timeout gem and have no choice.
There was an attempt to remove timeout from net http that was reverted:https://github.com/ruby/ruby/commit/f88bff770578583a708093f4a0d8b1483a1d2039
It IS safe to use when used inside a fiber scheduler like the async gem, because it swaps out the thread for a fiber timeout ↩︎
-
It’s ok to do once, up front, or controlled by mutexes. We’ll discuss that more in a bit. ↩︎
-
Sometimes you bake them into a cake for your friends 🎂. You just really love tempfiles 🥹. ↩︎
-
By “macros” I mean things like column encryption in Rails using
encrypts. Internally it uses a class level instance variable calledencrypted_attributesto track columns you are encrypting on that model.But it is only set once when the class is loaded. If the class is reloaded, it must be locked by a mutex to safely change that value - Rails has a “reloader” that handles this, for instance. ↩︎
-
Naive because this is a terribly inefficient way to calculate Fibonacci sequences, which is why it’s a great example for demonstrating how CPU intensive work causes CRuby context switching ↩︎
-
And most other languages ↩︎
-
Ruby 3.3 introduced the M:N thread scheduler, so there was a ton of refactoring of pthread internals. It may have been more impactful to threading than other versions - but every minor version is a year long large-scale effort that can easily have an impact on these private, internal behaviors ↩︎
-
This assumes you’re only loading classes once or safely handle reloads across threads (like Rails does) ↩︎
-
The reproduction steps are even a modified form of one of the issues https://github.com/attr-encrypted/attr_encrypted/issues/372 and here is the code that fixed the issue https://github.com/attr-encrypted/attr_encrypted/pull/320/files ↩︎
-
I’ll leave it to others to discuss the merits or pitfalls of using any globals at all, thread-local or otherwise 🤷🏻♂️ ↩︎
-
They’re totally susceptible to the copying state issue we just discussed but at least you’re aware of it now ↩︎
-
This could be achieved in a rack middleware as well, as opposed to an
after_action↩︎